Links to some of the stuff on this page...
6/2/2020 - This is a continuation of Ubuntu Stuff, now with Ubuntu 20.04 on a brand new ZaReason Limbo 9200a. Warning - editing system files and settings can break your computer (happens to me all the time!). Not responsible for anything that happens as a result of trying any of this stuff.
A few days ago my new ZaReason Limbo 9200a PC was delivered. The
system has a 6 core/12 thread AMD processor and plenty of storage.
The primary drive is a 1T M2 SSD, with 3 more conventional drives,
1T, 2T and 4T. It came with Ubuntu 20.04 pre-installed on the SSD.
The other drives automount via fstab. The 4T drive is for backups
so probably should disable it in fstab and mount only as needed.
Fixing up the Desktop Environment(s)
First tasks are to check out what I have and fix up a basic working environment. I'm an old-fashioned app menu panel and desktop icons guy, 25 years of expectations are not going to go away, just how I work. So first step is to find the terminal, sudo apt-get install synaptic to use that drag in everything else I need to be productive. Pretty much I followed what I did under VirtualBox to get a Gnome Panel "flashback" session and a MATE session, detailed in my 20.04 notes in Ubuntu Stuff. Give and take, things are different with real hardware. Afterwards had MATE and Flashback sessions set up the way I like in addition the stock Ubuntu session.
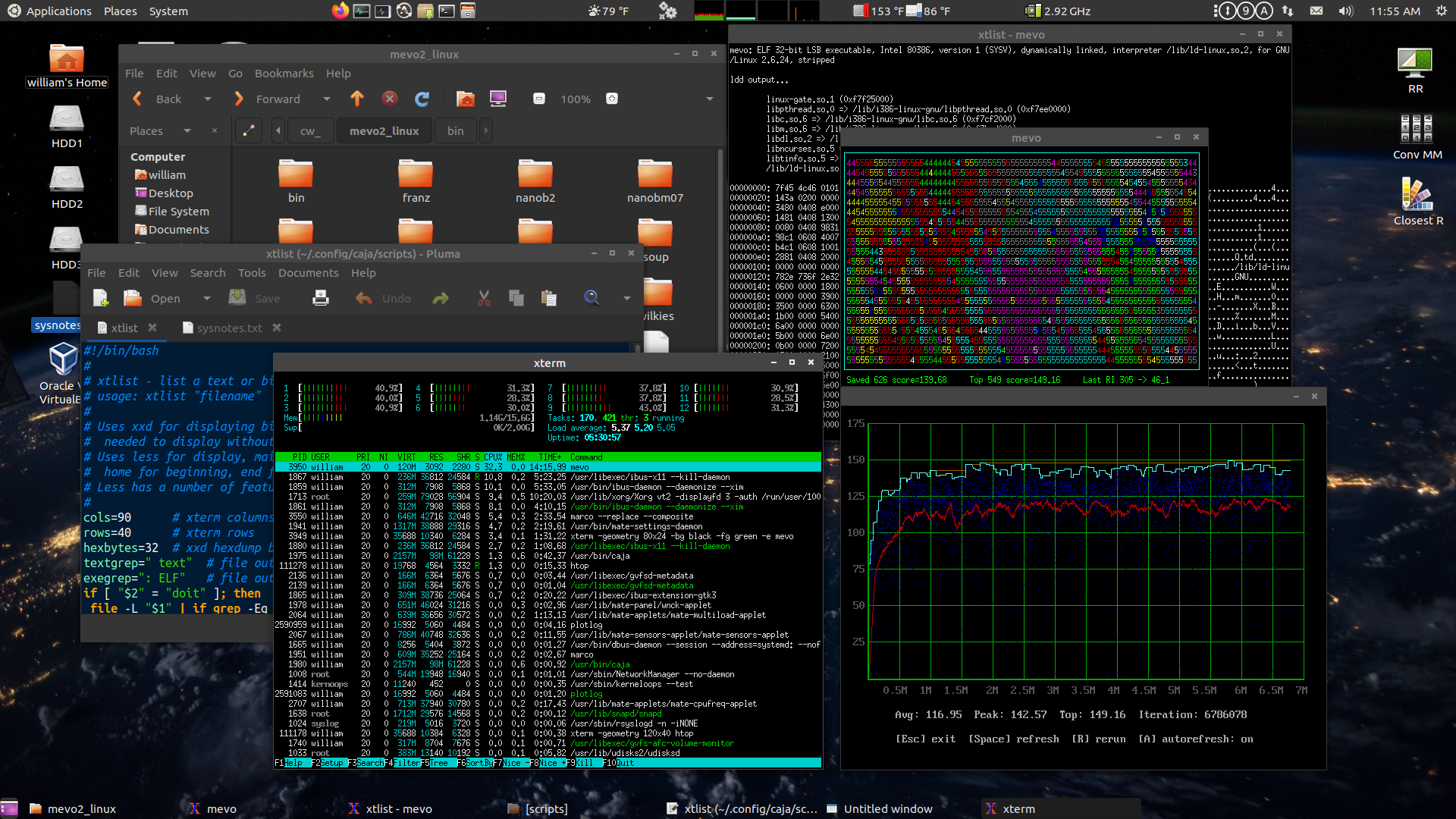
Here's the MATE session running some of my toys... (click for
big)
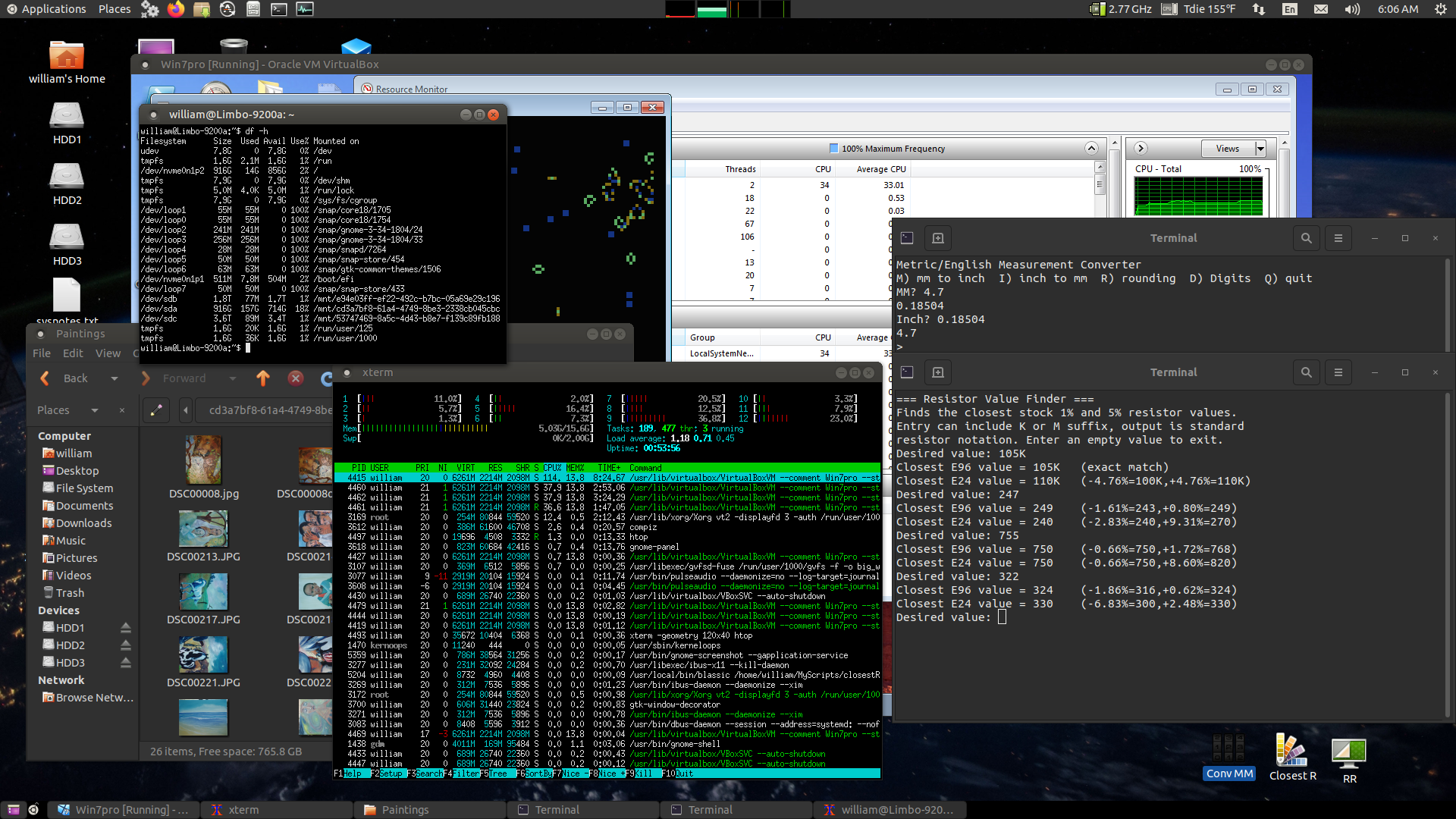
Here's the Flashback session...

It's getting there but took quite a bit of work - always does
with a fresh system.
Everything was done without modifying any root system files,
rather just installed packages and added a "mystartapps.sh" script
to the startup applications to selectively add or replace
components based on the $DESKTOP_SESSION variable. Even with the
Flashback session I still need MATE components, in particular Caja
since the Nautilus file manager no longer can handle the desktop.
Gnome Shell and Gnome Flashback both supply (different) components
that provide basic desktop functionality but I need my desktop to
function like a file manager. Caja is a fork of the Gnome 2
Nautilus and handles the desktop nicely, even better than the old
Gnome 2.
Here's a list of the desktop-related packages I installed along
with all their dependencies...
sudo apt-get install synaptic - installs a graphical package
manager
dconf-editor - for making adjustments to some of the settings
gnome-system-tools - adds useful things like users and groups
gnome-flashback - adds the gnome-flashback session(s) and
gnome-panel
gnome-tweak - Gnome-specific settings
mate-desktop-environment-core - pulls in caja and most of the
stuff needed to set up MATE
caja-open-terminal - adds a open terminal option, pulls in
mate-terminal
caja-admin - adds options to open folders and edit files as
administrator, pulls in the pluma editor
mate-applets - panel widgets
mate-indicator-applet - volume control clock etc
mate-notification-daemon - popup bubbles?
mate-tweak - MATE-specific settings
compiz - eliminates video tearing, better effects
indicator-sensors - temperature indicator for gnome panel and mate
panel
mate-sensors - temperature indicators for mate panel
mate-utils - optional extra utilities
Installing these and fully rebooting the system (logging out and
in isn't enough) adds extra login sessions for MATE, Flashback
(metacity) and Flashback (compiz). MATE compains about
incompatible widgets when starting up, possibly from running gnome
panel first (one of the first things I did was add gnome panel to
gnome shell so I could get around, but don't know if that's got
anything to do with it). Removed the incompatible widget and set
up the panels the way I want. Ran into a minor bug when setting up
the panels - sometimes selecting move on a widget made it go away
instead. Once set up I locked the items to avoid click mistakes.
The MATE session is pretty
much good to go now other than an issue with some of the dark
themes - when renaming files the cursor is invisible. To fix that
with my favorite dark theme I copied Adwaita-dark from
/usr/share/themes to ~/.themes, renamed it to
Adwaita-dark-modified, edited index.theme and changed both
instances of Adwaita-dark to Adwaita-dark-modified, and in the
gtk3.0 folder edited gtk.css and added the following (after the
import line):
.caja-desktop.view .entry,
.caja-navigation-window .view .entry {
color: blue;
background-color: gray;
caret-color: red;
}
For the Flashback sessions I added a script named
"mystartapps.sh" in my home directory containing the following...
#!/bin/bash if [ "$DESKTOP_SESSION" = "gnome-flashback-metacity" ];then caja -n --force-desktop & fi if [ "$DESKTOP_SESSION" = "gnome-flashback-compiz" ];then caja -n --force-desktop & fi
...made it executable and added it to Startup Applications. Note
- for this to work have to tell Flashback to not draw the desktop.
Use dconf Editor to navigate to org, gnome, gnome-flashback and
change the desktop setting to false.
It's starting to feel
like home now.
Originally I had Gnome Panel and Caja running (via
mystartapps.sh) in the original Ubuntu session just to get around
while setting up the other stuff, but with the other sessions
working I returned it to stock and fixed it up a bit...
Turns out the stock Ubuntu 20.04 desktop is more useful than I
thought. Originally I was under the impression that the new
desktop-icon extension didn't support desktop launchers (they had
generic icons and opened as text) but when a desktop file is
right-clicked there's an option to allow launching, when selected
the app icon appears and it works normally. Still have to open the
desktop in a file manager to do anything fancy, there's a
right-click option to do just that. A nice touch is almost
everywhere there's a right-click open in terminal option. A
cosmetic bug - the icons highlight when moused over but often the
highlight gets "stuck". Everything still works, just distracting.
Here's
a commit that mostly fixes the issue.
The side dock icons were a bit largish, using dconf Editor
navigated to org / gnome / shell / extensions / dash-to-dock and
changed dash-max-icon-size from 48 to 36. The dock isn't like
Gnome Panel where each window gets an icon, rather all instances
of an app are represented by a single icon with extra dots for
muliple instances. If no instances are open then clicking the icon
restores the most recently minimized window. If an instance is
already open then it displays thumbnails for each instance. More
clicks than a conventional panel but less clutter and distraction.
Another way to switch between apps is the Activities button on the
top panel which displays thumbnails for all windows.
The Gnome Shell extensions are Applications
Menu by fmuellner, system-monitor
by Cerin, and Sensory
Perception by HarlemSquirrel, the Tdie reading is from
indicator-sensors. With these extensions and after getting used to
the dock and other features I no longer need Gnome Panel and Caja
for this session. However sometimes I need the extra features of
the Caja desktop and file manager so I made a script to flip
between Caja and stock...
--------------- begin CajaDesktopOnOff -------------------------
#!/bin/bash if [ "$DESKTOP_SESSION" != "ubuntu" ];then zenity --title "Caja Desktop Control" --error \ --text="This script only works in the ubuntu session." exit fi b1=true b2=false if pgrep caja;then b1=false b2=true fi selection=$(zenity --title "Caja Desktop Control" --list --text \ "Select..." --radiolist --column "" --column "" --hide-header \ $b1 Caja $b2 Ubuntu) if [ "$selection" = "Caja" ];then caja -n --force-desktop & fi if [ "$selection" = "Ubuntu" ];then killall caja fi
--------------- end CajaDesktopOnOff ---------------------------
...and made a desktop launcher for it (with Caja). Defaults so
that OK is to flip. Make sure all Caja windows are closed or not
doing anything before flipping back to Ubuntu. Even though I don't
require a panel with the dock, it's still nice to have. One way
would be add it to mystartapps.sh...
if [ "$DESKTOP_SESSION" = "ubuntu" ];then gnome-panel --replace & fi
It actually launches both the top and bottom panels, the top
panel hides behind Gnome Shell's top panel so have to make sure
it's set to be the same size or smaller or bits of the panel will
peak through. Anything done to Gnome Panel also affects the
Flashback session. Instead of adding to the startup apps it would
be easy to make a GnomePanelOnOff script similar to the above..
Yes I think I'll do that...
--------------- begin GnomePanelOnOff -------------------------
#!/bin/bash if [ "$DESKTOP_SESSION" != "ubuntu" ];then zenity --title "Gnome Panel Control" --error \ --text="This script only works in the ubuntu session." exit fi b1=true b2=false if pgrep gnome-panel;then b1=false b2=true fi selection=$(zenity --title "Gnome Panel Control" --list --text \ "Select..." --radiolist --column "" --column "" --hide-header \ $b1 "Use Panel" $b2 "Remove Panel") if [ "$selection" = "Use Panel" ];then gnome-panel --replace & fi if [ "$selection" = "Remove Panel" ];then killall gnome-panel fi
--------------- end GnomePanelOnOff ---------------------------
That works.. boots up stock, can add/remove the extra components
as needed.
2/7/21 - lately Compiz has been interfering with some apps,
mostly Firefox, so set up a Mutter Flashback
session.
Getting my old 32-bit binaries to work was fairly easy - ran sudo
dpkg --add-architecture i386, reloaded the package list and
installed libc6-i386, lib32ncurses6, lib32readline8, lib32stdc++6,
libx11-6:i386, libncurses5:i386 and libreadline5:i386. Probably
don't need the lib32 versions but whatever. Oddly I couldn't find
libncurses5:i386 and libreadline5:i386 using the Synaptic package
manager (very necessary) but checked the repositories on the web
and it said it was there, apt-get install worked. Bug in
synaptic's search function? No matter, all my old corewar toys and
precompiled 32-bit FreeBasic binaries work fine.. used MEVO as a
load simulator in the earlier screen shots.
Added/installed my scripts I use frequently - in particular
AddToApplications and AddToFileTypes to make up for the lack of
user-adjustable associations. MATE/Caja already has an option for
making app launchers so don't really need CreateShortcut but added
anyway, sometimes I like to make launchers that are not on the
desktop. Compiled and installed Blassic and my crude but useful
work scripts (conv_mm and closestR). Installed the FreeBasic
binary package along with a bunch of dev packages it needs to
work. Compiled and installed Atari800, had to install the sdl1.2
dev packages to get a graphical version. There's also a fairly
recent version in the repositories, no longer needs ROM files
thanks to Alterra. The Vice C64 emulator works well, much better
than it did under VirtualBox.
Tried to install IrfanView in wine but it needs mfc42.dll. Copied
the file to the system32 folder, no joy. Googled.. oh run regsvr32
mfc42.dll, no joy. Moved it to the windows folder then regsvr32
worked. My script doesn't... oh nice got a 64-bit wine now,
install location is different, edited the script, now it works.
There are plenty of native Linux image editors but I like
IrfanView for simple/common stuff, been using it since before
Windows 95.
No DosEmu/FreeDos in the repos. One of the things I like about
DosEmu is it's scriptable - rigged it up so I could right-click a
.bas file and run it in QBasic, very handy for "one offs". DosBox
kind of works but totally not the same. I suppose I don't really
"need" dos anymore, FreeBasic and my fbcscript script works for
quick programs, but I just want my old stuff. Tried compiling
DosEmu from source but that ended up looking futile - configure
was bugging out trying to figure out what glibc version I have
(was kind of comical.. puked the environment variables and a bunch
of other junk then declared I had version 0 and I needed a newer
version... nice. Even if I patched over that chances of
successfully compiling and installing are too low to put in the
work. Thought about transplanting what I'm running under 12.04 but
it's a lot of files and I'm trying to avoid messing with anything
above /usr/local as much as possible.
Found a DosEmu/FreeDos deb for Ubuntu 19.10 and installed that
with gdebi, appeared to work but after copying over my dos
configuration and environment found that it won't run anything
that uses DMPI (XMS), or most games. This bug has cropped up
before, there was a fix but it no longer works and likely won't
ever work (it works on my 12.04 system but only because it no
longer updates.. kernel updates often broke it). Disabled XMS in
the config file, still very useful for running QBasic and other
normal dos apps. My old qbasic_pause script for right-clicking bas
files still works. For games, installed DosBox and rigged it so it
booted into the same environment with the same path, works and can
make the screen bigger. Got Dos.
Thoughts so far
MATE - probably my favorite environment, certainly has my
favorite components. Very configurable and expands on the
traditional desktop concept. On my system the Marco window manager
flickers when watching video, installing and selecting Compiz
fixes that. The panel is easier to set up and adjust, widgets can
be placed anywhere on the panel and it has a better temperature
widget than Gnome. Sometimes things bugs out when moving, once set
up and locked it's fine. The main bug/feature that makes me not
use it as much is the screen blanks after inactivity and I can't
find a setting that controls that.
FlashBack - the default desktop is not useful for me, can't
arrange the icons (the options are grayed out). Works well when
the Flashback desktop is turned off using dconf-editor and caja -n
--force-desktop is run at startup to handle the desktop. MATE and
Flashback can share themes if compatible components are chosen.
Gnome Panel isn't as configurable as MATE's panel - can't make
transparent, panel widget and icon positioning is less flexible.
But it is more stable, no need to lock since it stays locked
unless alt is pressed. Been using it for 7 years so used to it.
The Metacity window manager flickers too, install Compiz to fix.
With both MATE and Flashback I haven't figured out how to switch
the clock to day/date/time format [one solution is use app
indicator rather than app indicator complete, and use the separate
clock applet, still somehow I got app indicator complete to output
the full format date/time on 12.04].
Ubuntu/Gnome Shell - I'm liking this session more and more. The
side dock took a bit of getting used to but the more I used it the
more I like it. Even the Activities overview is useful - these
features work better on a fast machine with a large monitor. The
new desktop-icons extension works well - the manipulation
functions are limited but once set up the icons are beautiful and
perfectly functional. I still need the more advanced stuff but not
all the time, sometimes it's nice to simplify. For most tasks the
stock environment is fine and perhaps less to mess with means less
distraction. The fancy stuff is all there, behind a couple
double-clicks.
The machine itself is awesome. Got to get the memory module fixed
but that's not a big deal.. 16 gigs is plenty. It's crazy fast..
to me anyway, spec-wise it's only about midrange to average.
6/5/20 - To make sure the system wasn't stressing the solid state
disk too much I made a disk monitor script...
------------ begin diskrwmon -----------------
#!/bin/bash # diskrwmon - original 200602, comments 200605 # script to show uptime/load, temperature, cpu and disk I/O stats # requires xterm, sensors from lm-sensors and iostat from sysstat # semi-specific specific to my Ubuntu 20.04 system # if [ "$1" != "" ];then # now running in xterm (presumably) while [ 0 ]; do # loop until terminal window closed echo -ne "\033[1;1H" # home cursor echo "" uptime echo "" # -f for Fahrenheit, omit for C # first grep isolates desired sensor, # second grep highlights from + to end of line sensors -f | grep "Tdie:" | grep --color "+.*$" # run iostat to get a cpu usage report, trim blank lines iostat -c | grep " " echo "" # run iostat to get a human-formatted 80-column disk report, # first displaying cumulative since boot, then over 10 seconds # for older versions of iostat use iostat -dh 10 2 (not as pretty) iostat -dhs 10 2 done else # no parm so launch in an xterm window # adjust geometry rows as needed to avoid scrolling xterm -geometry 80x42 -e "$0" doit fi
------------ end diskrwmon -------------------
The script displays two iostat disk reports every 10 seconds, the
first is cumulative since the last boot, the second over the last
10 seconds. Also shows uptime (useful for interpreting the
cumulative report), temperature and CPU usage. It is
system-specific, have to edit to set which sensor to display and
adjust the terminal height which depends on how many file systems
are mounted. On my system the output looks like...
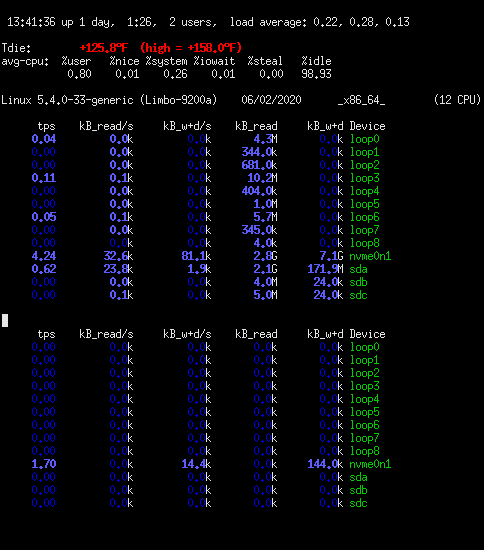
[after an update ended up with loop0-loop9 so had to change the
xterm line to 80x44 to compensate]
The system buffers non-critical writes to avoid hammering the
file system with small writes, on a solid state disk writing a
single byte can result in kilobytes to megabytes being actually
written depending on the nature of the storage system. Calculating
lifetime is tricky - according to my old crude and probably wildly
inaccurate ssd life program, 81.1
blocks per second sustained with an endurance of 1000 writes per
block on a 1T drive with 500G free results in a lifetime of a bit
over 1 year, that's a bit concerning (and hope it's very wrong).
That program was written in the EEE PC days, things are different
now but regardless the goal is to minimize writes/per second. I
will probably move /home to sda to get it off of the SSD, and
mount the SSD with noatime - with access time even reading a file
writes data. One thing for sure, the solid state disk is very fast
compared to a normal disk drive.
[6/6/20] Another way to calculate lifetime is by how many times
the drive can be rewritten. Say the endurance is 1000 writes, for
a 1T drive that's 1000T of writes before errors occur. If each
write causes 5 times the data to be written (amplification factor)
then say 7 gigs/day actually writes 35 gigs/day, or 12.775T per
year. 1000/12.775 ~= 78 years. Even if endurace was only 300
that's still > 20 years. But that seems unrealistic... frequent
writes of just a few bytes (logs, access time etc) can still
trigger megabytes of actual writes and greatly shorten lifetime,
so best to set noatime on the SSD and move at least /var/log to a
normal disk.
Those 9 loop file systems are from "snap", Ubuntu's new packaging system. I have no snap apps installed yet it read over 20 megabytes of something from something.. and every bit of data read causes data to be written in the form of access time updates - definitely need to add noatime to the SSD mount entry. As I have written earlier in my Ubuntu Stuff Notes I'm not a fan of snap - it's opaque, pulls in huge dependencies, updates outside of the package system (from what I've heard sometimes even when the program is running, causing loss of work), and in my testing in a VM didn't work half the time - but for now left it in place. In my VirtualBox test install I definitely noticed the extra drag and removed as much of snap as I could. This system has enough resources to not notice the extra snap drag, might let it be for now to study it but if it misbehaves it's gone.
Then things went south. While
swapping around ram modules to troubleshoot the missing memory
issue, this happened...

...that ain't no LED, that's a trace glowing cherry red! Ouch!!!!
Definitely a "I need a beer" moment [but turned out to be a weird
indicator light after all, see below]. ZaReason offered to send me
a replacement motherboard but after this I'm inclined to leave the
surgery to them. I was planning on eventually getting another
system anyway (I work better if my work is on a separate
system/monitor) so when the new system arrives will swap the
drives and send this one in for repair. I thought about whether or
not to post about this, but decided to share it as a lesson that
when working on computers unexpected things can happen. And it's
kind of a cool picture, seen (and repaired) plenty of fried traces
but caught this one in the act [of doing a damn good job of
impersonating a trace on fire].
7/3/20 - Got the new machine, which has a ASRock B450M Pro4
motherboard, swapped the drives from the first machine to the new
machine and it came up fine, just like I left it (one of the
things I love about Linux). Unlike the Giga-Byte MB with this one
I didn't have to adjust BIOS settings to get VirtualBox to work.
With that sorted, turned my attention to the first broken machine.
First thing I noticed was one of the ram modules wasn't seated
properly, fixed that but no go, nothing but the drives clicking,
that trace lighting up and a bit of an electrical smell like
something was getting hot. But it wasn't the trace.. cautiously
touched it expecting it to leave a mark but it was cool, it was an
indicator light after all just like ZaReason thought it was (good
going Giga-Byte.. I know let's make a useless light that looks
just like a trace on fire - brilliant!). The real problem was the
power connector on the motherboard was loose and barely touching
on one side, probably knocked it loose while trying to swap around
RAM modules in the dark. Inspected the connector, no apparent
damage, plugged in all the way and the computer booted fine, got
back the full 32 gigs of ram, apparently that was just a
mis-seated RAM module. Lesson - don't work on a PC in the dark!!!
Glad it's sorted and that I don't have to send anything back for
repair.
The new machine "only" has 16 gigs of RAM but that's probably
fine.. less memory to experience a cosmic ray induced bit flip
(not sure how often that happens but without ECM I'd likely not
know unless something bugged out), less chance of file corruption
since Linux uses extra memory as a file cache. Perhaps I should
make a program that allocates say a gig of memory and periodically
checks it for changes.
7/4/20 - Besides iostat, a handy command for determining what is
being written is "sudo find / -xdev -mmin 1" which lists the files
that have been written to in the last minute. The command itself
always updates the auth.log and system.journal files. To help
minimize writes to the SSD I created a "home_rust" folder on a
spinning drive and from my home folder copied .cache, .config and
.mozilla to it, replacing them with symlinks. That got rid of the
majority of writes to the solid state drive, especially when
browsing the web. I could further reduce writes with some
system-level surgury - mount the SSD with noatime and move at
least /var/log and maybe /var/lib/NetworkManager to spinning rust.
Access time is marginally useful and files that are repeatedly
read tend to live in the memory cache and don't update the file
access time (not a bug please don't fix). Logs are another story..
every time a program is opened or some GTK thing doesn't feel
happy it spews the logs, and every new network connection updates
NetworkManager's timestamps. How much effect this has is not
clear, depends on how smart the SSD is regarding keeping partially
empty pages for small writes without triggering page erases/moves
(write amplification).. but would feel better if it didn't happen
at all.
On the other hand, one must be very careful moving system
folders, particularly to a drive that can be unmounted with one
misplaced click. The few home data folders I moved are all
basically non-critical - apps complain, settings go away until
remounted - but system directories are another story. No idea how
systemd would react if it found itself unable to write its logs.
Also the matter of making the switch while the system is running,
can get away with it with home directories but trickier trying to
move log that way, a log write might occur before the process
completes. Nahh.. unless I can see evidence that it's actually
hurting the drive lifetime better leave it alone, and from what I
can tell SSD's have come a long way since the days of the EEE
netbook when one had to worry about such things.
I found a tool called nvme that reads the NVMe (SSD) logs and
generates a report, it's in the nvme-cli package. After
installing, running "sudo nvme smart-log /dev/nvme0n1" (in my
case) generates a report that includes the number of blocks
written and estimated lifetime used. Be super careful with that
tool, some commands will make the drive go bye-bye in a "flash".
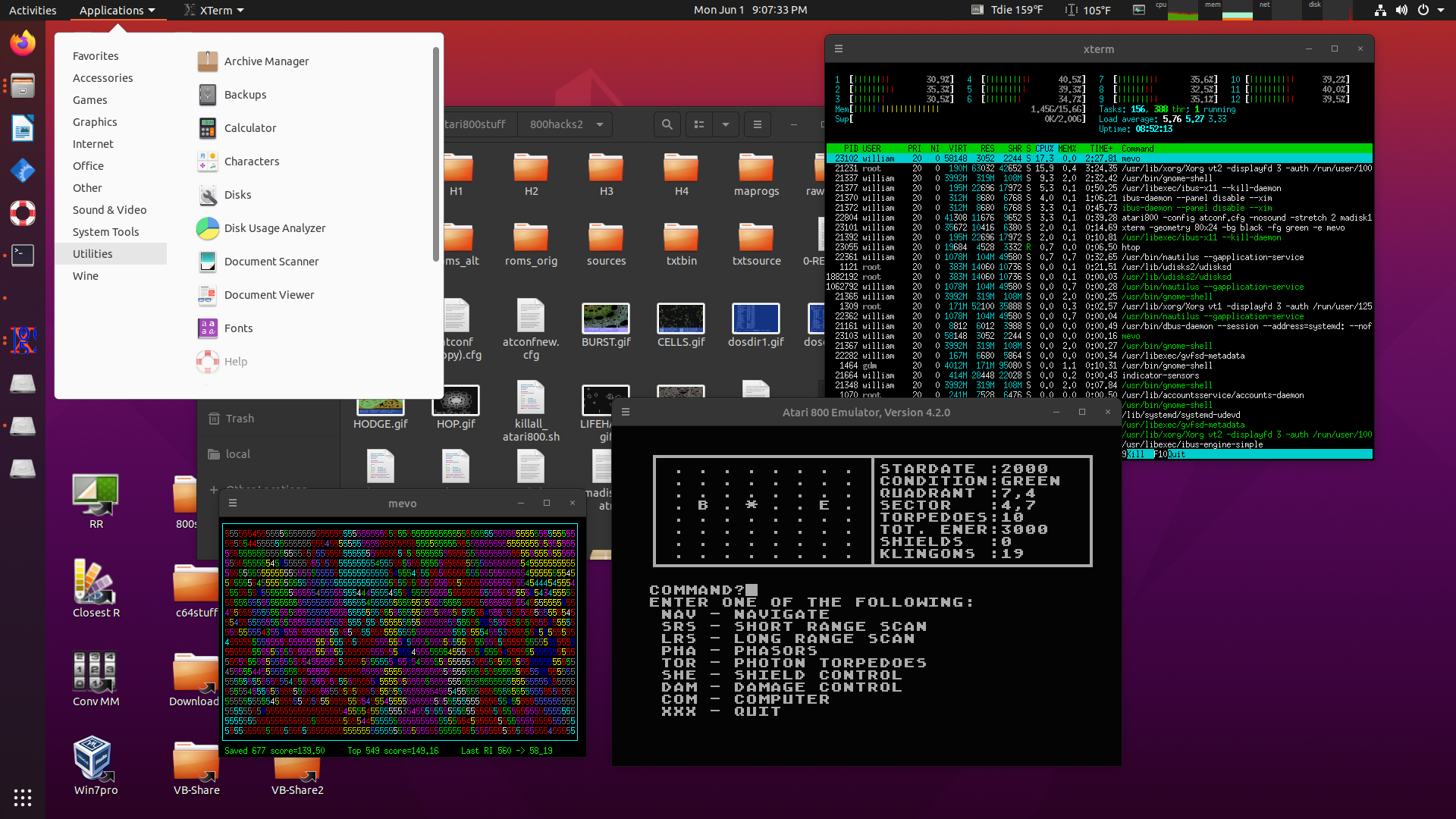
Here's a screen-shot... (click for bigger)
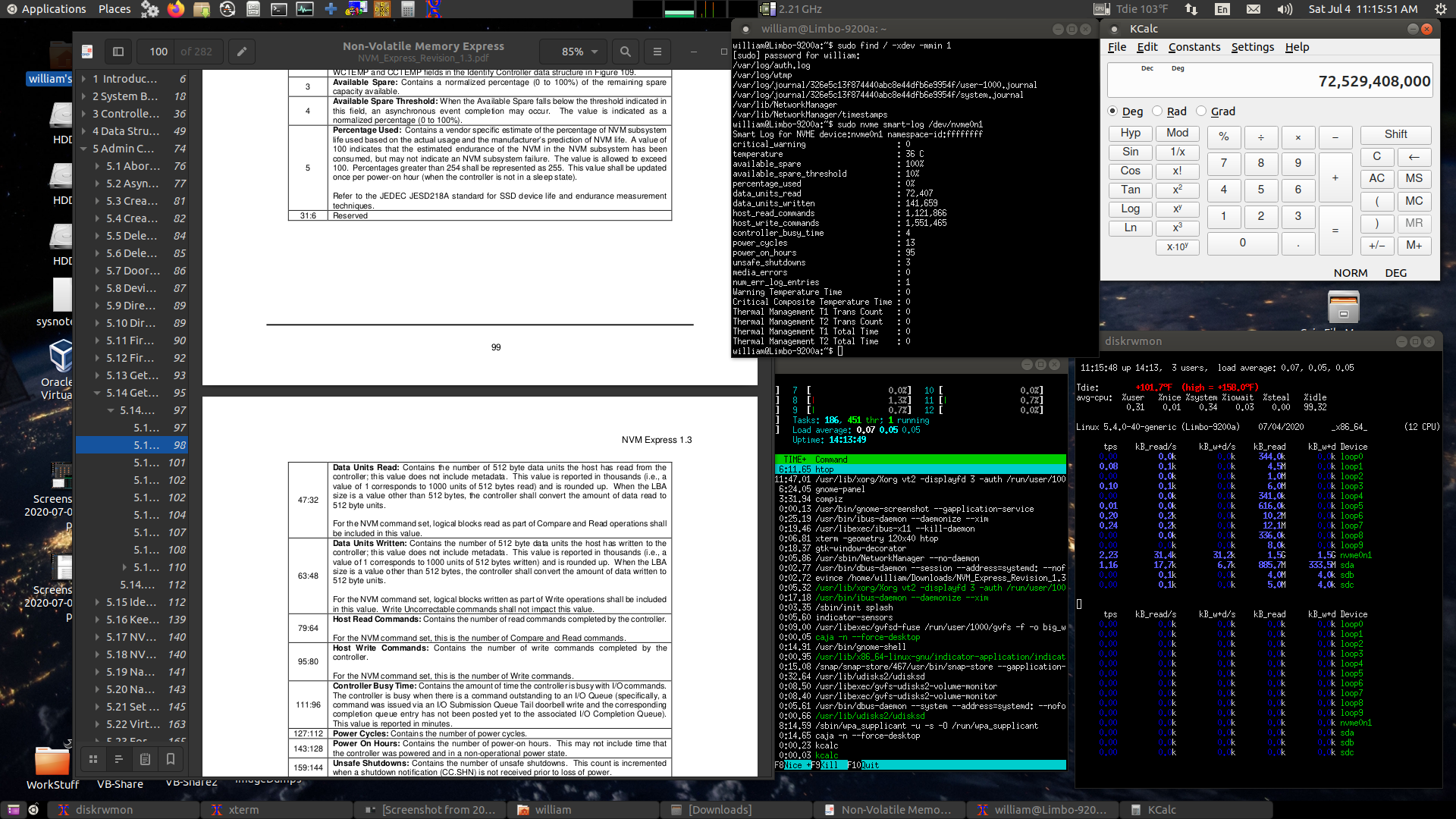
As can be seen in this screenshot, in the 14-odd hours the system
has been up it has written 1.5G of data to the SSD (this probably
does not include any write amplification and housekeeping but
seems like quite a lot). When the system is idle writes tend
toward 0, most writes that do occur go to sda thanks to moving
those home folders. When FireFox is open it writes quite a bit to
sda.. in the case of Yahoo megs at a time. Almost all idle writes
to nvme0n1 even with FireFox open are to the logs and the
NetworkManager timestamp. According to nvme smart-log the drive
has logged 141,659 data unit writes, each one 512,000 bytes, for a
total of 72,529,408,000 bytes written. Or ~73 gigabytes over
the 95 hours this drive has been in use. The money figure is
percentage used, at 0%. With that in mind copying all my work data
to the SSD.. 137 gigs worth (which resulted in about 128 gigs of
writes according to iostat.. probably a base 2 vs base 10
difference). After that operation, data units written increased to
410,508, or ~210 gigabytes written, percentage used still 0.
Windows 7 (in VirtualBox) running from the SSD generates lots of
idle writes but wow is it snappy! Seems to settle down after
awhile.
7/6/20 - Getting my HP2652 wireless printer working was tricky..
first had to get the "HP Direct" connection going, figuring out
the password etc (press wireless and info buttons together to
print the info, ended up being 123456), and trying to set it up.
Running hplip was no use, even after installing hplip-gui. Add on
the printer setup screen found it but it was non-functional,
complaining it couldn't find a driver. Had to go to Additional
Printer Settings and click Add - this saw the printer but appeared
to lock up. After trying a few times figured out it was waiting
for me to click the wireless button on the printer, after doing
that it worked. Manual says the wireless LED should stop blinking
but never did, but seems to work. This printer doesn't seem to be
capable of printing a full-size page so have to resize to 80-85%
to keep from cutting off the margins (same as how it behaved with
Ubuntu 12.04). Adobe Reader does a better job of recognizing the
printer's capabilities, installed the last avalable version
(9.5.5), 32-bit-only so have to have that set up. To get acroread
to show up in Gnome's associations had to use my AddToApplications
script on the acroread binary then select it in the file open-with
properties. Showed up automatically in Caja's associations.
Headphones didn't work, just had sound through the HDMI monitor
and no other selection in the Sound Settings Output section.
Rebooted into the BIOS setup and changed the Front Panel sound
setting to AC97, now it shows up in Sound Settings and works.
SSD lifetime again
7/14/20 - Here's a (probably) better SSD lifetime estimator...
(got to be better than what I was using for the EEE PC)
------- begin SSDlife2 ------------
#!/usr/local/bin/blassic print "===== SSD life estimator =====" input "Drive capacity (gigabytes) ",dc input "Capacity used (gigabytes) ",cu input "Write endurance (times) ",we input "Data written (gigabytes) ",dw input "Timeframe (hours) ",tf ' calculate write amplification (guessing!) wa = 1 + ((cu / dc)^2 * 5) : print "wa = ";wa ' calculate amount written aw = dw * wa ' calculate gigs per hour gph = aw / tf : print "gph = ";gph ' calculate total write capacity twc = dc * we ' calculate lifetime in hours hours = twc / gph : print "hours = ";hours ' calculate days days = hours / 24 : print "days = ";days ' calculate years years = days / 365.24: print "years = ";years input "----- press enter to exit ----- ",a system
------- end SSDlife2 --------------
This one takes into account that modern SSD's (probably) better
handle write amplification, in this program it's calculated based
on capacity used compared to total capacity and likely
overestimates - as written 20% full results in WA=1.2 and 50% full
results in WA=2.25, no idea how close to reality that is but for
my workload where I'm constantly punching holes in huge files I'd
rather error on the side of caution. Reduce the 5 or increase the
2 in the wa formula for a less drastic increase or enter 0 for
capacity used to fix write amplification to 1. The write endurance
input is how many times the entire capacity of the drive can be
rewritten, for my WDC 1T (1000G) drive it is specified as 600T so
that would be 600 times. Data written and timeframe can come from
iostat and uptime or from the nvme smart-log command.
My iostat figure for the last 17.75 hours is 32.7G so 1000G
capacity, 200G used, 600 times, 32.7G over 17.75 hours computes to
a lifetime of 30.96 years. Going by the nvme smart-log figures,
since using this drive it's performed 604,630 writes of 512,000
bytes each, or 309.57G (base 10 G's) over 179 hours. I'm pretty
sure that does not include housekeeping so entering 1000, 200,
600, 309.57, 179 - that works out to 32.98 years. So far so good
but also I haven't been using the drive all that heavily yet.
One thing I've noticed (also recall this from the EEE PC days),
whenever trim is issued, typically once a week with a stock Ubuntu
install, iostat will report the entire unused capacity as having
been rewritten. I seriously doubt that's actually the case - trim
might trigger some writes from reorganization in the interest of
making future writes more efficient but if it actually wrote 773G
of data it would have taken a long time for the drive to become
responsive after issuing the trim (no perceivable delay), plus
iostat (nor any utility as far as I can tell) can't actually tell
what's going on inside the drive beyond the information the drive
offers up, which (again as far as I can tell) does not include
internal housekeeping.
Backups
The system has a 1T SSD and 1T, 2T and 4T regular drives. The
plan was to put OS and work files on the SSD, static
not-that-important files and constantly changing files on the 1T
so they won't consume SSD capacity, big stuff on the 2T drive and
use the 4T drive for local in-the-machine backups. In addition to
this I also periodically copy the really important stuff to an
external drive and/or email off-site, but that stuff is only a
small fraction of the total capacity, for the rest backing up
internally and periodically swapping out the backup drive is
sufficient. The biggest risk of data loss is by far fumble-fingers
which happens all the time, followed by single-drive failure, rare
but when it happens it takes out a lot. Internal backups mitigate
both of the more common scenarios and cycled drives and off-site
backups mitigate other scenarios. I back up my system files while
the system is running (everything except for stuff like /tmp /dev
/media /proc and anything under /mnt is done separately to avoid
backing up the backup drive), not exactly proper but in my
experience (had my boot drive fail before) that is sufficient to
restore the system to working condition.
Right now there's nothing all that important in the new machine
beyond time setting it all up, but now that I'm starting to do
real work it's time to get backups working. Key word is working!
First thing I tried was the backup program included with Ubuntu -
Deja Dup, a front-end for duplicity. Specified what I wanted to
back up and where to, it appeared to work except kept asking me if
I wanted to copy the contents of symbolic links (no of course) and
once the backup was completed it just sat there doing nothing with
no disk or cpu activity. Only options were cancel and resume later
so clicked the latter. It appeared to work, saved a bunch of
archives and in Nautilus the revert to a previous version option
seemed to recognize the snapshot. I soon learned those backups
were basically useless, at least for the way my fingers fumble.
After mistyping a chmod command and wiping out my work folder
(could have fixed it.. accidentally removed execute from all the
folders but since there wasn't any real work saved there yet good
time to test the backups) discovered that Deja Dup was incapable
of restoring the folder, restored from the source drive. With that
fixed, tried restoring and reverting test files, now it couldn't
find the snapshot at all. Worse, the archive files were
incomprehensibly named, restoring anything manually looked next to
impossible. Maybe it works for some but it failed for me bigtime
on the first try. Next.
Fired up Synaptic and found a backup program called "Back in
time", installed backintime-qt and as far as I can tell it works
perfectly. It uses rsync, same as what I used for my old backup
script but implemented better - as usual with rsync it backs up
only files that have changed but unlike my homemade solution the
unchanged files are hard-linked with previous snapshots so that
many snapshots can be taken, each appearing as a compete copy of
the file system but without consuming extra space for duplicated
content. Awesome! Restore options are apparently limited to full
restores but it doesn't matter, if a file or folder gets wiped out
simply open up the backup folder, navigate to it and drag it back,
no need to even run the backup program. When making a snapshot I
run it as root (using the provided menu entry) and it gets all the
symlinks permissions and ownerships right - the snapshot tree is
simply a copy of the filesystem. One limitation is it doesn't back
up symlinks in the root directory, at least not when selecting
them as folders, don't want to back up all of root as that would
presumably recurse into the backup drive under /mnt. Not a
problem, just backed those up separately, they will never change.
Permissions
I'm gonna have to get an external drive and reformat it ext4,
this problem crops up every time I use a NTFS-formatted drive to
transfer files. At least symlinks seem to be preserved but file
permissions get all out of whack, upon copying back to the new
system everything seems to come out 777 - executable, by anyone.
Same with directories, all get set to 1777. Not all that worried
about the directory permissions but for the files it causes any
text file to open up the run dialog instead of an editor or
whatever else it's associated to, which is quite irritating. Tried
to fix it using recursive chmod commands but they never seemed to
recurse right and one syntax slip and there goes all the stuff,
which happened (then discovered my backups were no good). I used
to use a perl script called "deep" for recursively fixing
permissions but perl 5.30 no longer supports File::Glob::glob,
error message said to replace with File::Glob:bsd_glob but that
didn't work. So hacked up my own crude solution...
------- begin fixallperms.sh ---------------
#!/bin/bash # this script resets the permissions of all files with extensions # in and under the current directory to 644 (non-executable) # and all files that match exelist below to 755 (executable) # files without extensions are ignored exelist="*.sh *.exe *.bat *.com *.blassic *.fbc" basedir=`pwd` find . -type d -readable | while read -r filedir;do cd "$basedir" cd "$filedir" for file in *.*;do if [ -f "$file" ];then echo "$basedir/$filedir/$file" chmod 644 "$file" fi done for file in $exelist;do if [ -f "$file" ];then echo "EXE - $basedir/$filedir/$file" chmod 755 "$file" fi done done
------- end fixallperms.sh -----------------
The script recursively applies chmod to all files in and under
the current directory (my way.. got tired of destroying stuff
trying to make -R work), first setting all files with extensions
to 644 (non-executable, ignores files without a dot extension i.e.
most binaries) then sets particular extensions I want to be
executable to 755. First it gets the current working directory,
then uses find to generate a list of subdirectories (including the
current directory) which it pipes to a while read loop, then for
each directory changes to the base directory then the relative
find directory, uses for to reset all files in that directory to
644 then uses for again to set executable files to 755. Use with
caution! Don't try to run this on an entire home directory and
definitely not on system directories, it is meant only for fixing
permissions within specific folders after they got wiped out from
transferring via a NTFS or FAT drive.
Working through other issues
7/15/20 (replacing previous to simplify.. editing this on the new
machine)
Gnome Panel's weather app is broken, the forecast doesn't work
and the option to enable the radar map url doesn't stay checked.
The similar app for MATE panel works fine and with the same url.
Found an app called gnome-weather, not a panel app and doesn't
have a radar pane but works and has a nice hourly forecast
feature. The radar was handy for a quick check, for
interactive/moving displays always went to the local TV radar page
anyway. Making a minimal window that just shows a specified web
page doesn't look that difficult, found
this example.
MATE is wonderful and very glad it exists (especially the Caja
file manager), but it does have some rough edges. Some have been
previously noted... trying to move panel widgets often results in
removing them instead (or appearing to have been removed). Once
the panel is set up it is stable and works fine, but noticed
another oddity.. with some widgets (including launchers and the
menu) checking the Lock option does not deactivate the remove
option. There's a cosmetic one- or two-off bug in the MATE system
settings app... in the left pane selecting a section jumps to it
but highlights a section below it. The big one is after about
15-30 minutes of no mouse or keyboard activity (haven't timed) the
screen blanks, even when watching video. It doesn't do that in a
VM, on my old 12.04 machine I use 20.04 running MATE in a VM to
watch Netflix Hulu etc and it works fine. Have not found a setting
to control that. MATE's settings app doesn't have a power section
but in Gnome the screen blank function is set to never. Despite a
few rough spots I generally like MATE better - uses less memory,
better panel applets, has a really cool Appearance app for
selecting and saving theme combinations (which transfer to Gnome)
- but the screen blanking thing usually drives me back to Gnome
Flashback.
The Caja file manager does not properly generate thumbnails for
PDF files. So far the only workaround I have found is to open the
folder in Nautilus (aka Files) to create the thumbnails, once
created then Caja displays the thumbnails fine. But not for any
newly created PDF files until refreshed by opening in Nautilus.
Only PDF files seem to be affected, thumbnails for images are
fine. Setting Caja to be the default file manager didn't fix the
issue but did add a handy right-click to Open in Files (before had
to search for it in a list of apps) and makes Gnome Panel's Places
entries open in Caja.
It takes a combination
It would be nice if there was a single distribution that provided a well-functioning traditional desktop out-of-the-box, but from what I can see there isn't, at least not without some tweaking. MATE is very close - close enough that if the screen blank thing was fixed I'd probably spend most of my time in the MATE session, but there are still some settings I can only access from a Gnome session and MATE isn't quite as stable as the good old Gnome 2.3x system from which it was forked (no doubt from having to convert to GTK3 and all the other modern stuff). I do hope they keep up development, in my opinion as far as Linux desktop GUI's it's the best thing going right now for providing a traditional interface.
Gnome... if not for simplifying Nautilus to the point of hardly
being able to use it, and especially removing its desktop
functionality, Gnome would still be fine. I have an earlier
version of Gnome 3 on my old 12.04 system and it works more or
less like a better version of Gnome 2. Removing things like being
able to run Nautilus scripts without files specified is bad enough
(many of my scripts operate on the current directory, stuff like
play all media files etc), but removing the ability to manage the
desktop is too much, the only way to work around that is to use
another file manager that can provide that functionality and right
now that pretty much means Caja. Even Nemo can no longer handle
the desktop. Developers have scrambled to provide at least
something for the desktop - a Gnome Shell extension and whatever
that thing is that ships with the stock Flashback session - but
these are not good replacements. Basically they're just launcher
panels and provide little or no actual file manager abilities,
better than nothing but require opening the desktop in a file
manager to do anything beyond simple basics.
My productivity depends on my desktop being an extension of my
file manager with the added ability of remembering icon positions
and other desktop-specific stuff like creating launchers. Like it
has been for 25 years! Every extra click or moment spent having to
do something the OS can no longer do is time taken away from
actually getting stuff done. The new interfaces just don't cut it.
I can see what they are after - most people spend their time
mostly in one app, but my job requires not only running design
stuff in a window running Windows but also many other utilities..
terminals, calculators, text editors, file viewers, dumb but
important little utilities I type stuff into and they give me
answers. Sometimes I have half a dozen or more windows open at
once so I need a good panel for one-click access. Thankfully Gnome
Panel is still provided, and the Flashback session doesn't mind
that I use Caja for my desktop and default file manager. Almost
like they knew... I did here talk in the early days of 20.04
development about using Caja to provide the desktop.
So it seems I'm set now, thanks to the MATE project. Gnome is still fine, all the extra configuration trouble was basically caused by removing functionality from a single app, which I still need to use to compensate for Caja's PDF thumbnail issue.
Most of the other apps I use seem to work fine.. gFTP and gerbv are in the repository, pretty much all of my old simple binaries (32 and 64 bit) function as-is with minimal fiddling. For editing I use SeaMonkey Composer, not in the repository but "installing" is easy, simply download and extract anywhere and run it. Installing was just putting a symlink to it in /usr/local/bin and making another script that runs it with --edit to run composer, used my AddToApplications script to add desktop entries to make it easier to associate and added menu entries. Also use it with the --news option for newsgroups. Wasn't quite right with my dark system theme but came with another theme that works great.
Hmmm... not as good as my 12.04 system?
7/31/20 - Been doing real work with the new system and ran into
some deficiencies. VirtualBox running Windows 7 and Altium work
well, especially nice on the solid state disk (hammers it with
disk writes but according to my lifetime calculator it's good for
another 43 years). Installed FreeCAD, mainly for working with 3D
step files. At almost a gig it's overkill for a step file viewer
but probably is good for other stuff. For all that clicking help
just shows an error saying I need to install the documentation
package (which doesn't exist in the repository). The SeaMonkey web
browser and editor works great, so long as DRM isn't involved, got
FireFox for that. Don't like the new FireFox UI. what used to be 2
clicks to find a bookmark is now several more clicks, the old
Mozilla/FireFox interface is so much better. The new Gnome
Nautilus file manager still sucks, and Caja has a tendency to get
unstable sometimes, besides the PDF preview issue it often hangs
just trying to preview simple graphics. Caja does better with
associations, Nautilus sometimes doesn't pick up newly added
associations and makes me click more to get to what it does
recognize, no simple "open with" list. So I can choose stability
and previews or usability and bugs. My old 12.04 Gnome 3 system is
much better.
Things really got frustrating when it came time to put together
my circuit docs. I use the pdftops and ps2eps command line
utilities to make (sometimes rotated) eps files for embedding in
documentation. Pdftops was already installed, installed ps2eps.
These are very simple utilities but somehow failed - the ps2eps -R
+ command fails to also rotate the bounding box, no amount of
command line fiddling could fix. Uses GhostScript in the
background, probably what's failing. It gets much worse - the
included version of LibreOffice is just broken. When trying to
open an empty file (from Templates to start a new document) it
opens up an unrefreshed window with the desktop background showing
through. Works when started from the app menu, just not
right-clicking a file from the file manager. Traced the issue to
the Compiz window manager, opens OK when using Metacity or Mutter.
With that sorted, it's still broken - doing very simple stuff like
writing some text, hitting enter a couple times then dragging in
an image fails - inserts the image before the text instead of
where I told it to. Unusable. Might be able to fix by uninstalling
the distro version and manually installing downloaded debs, that's
what I do on my old system running LibreOffice 5. The imagemagick
convert -crop command doesn't properly update the dimensions, to
fix have to load the resulting cropped image into IrfanView (an
old Windows program I run with wine) and resave. The new software
as it stands now is unsuitable for doing documentation, to get my
work done had to zip up my work folder, copy it to a USB drive and
copy it to my old 12.04 system.
8/1/20 - Having to copy work back and forth to edit new stuff on
the old system is not a tenable situation, so Take Two.
Uninstalled all traces of LibreOffice 6, copied over the
pile-of-debs for version 5.2.3 from my old computer and installed
them using sudo dpkg -i *.deb. The older version works fine, no
problems with Compiz. Not sure why version 6 was so bad but it
reflects my experience with some new software in general,
especially new versions of programs I have used for years - all
those shiny new features (that I rarely need) tend to take the
focus away from the basic boring stuff (that I absolutely need)
and I usually notice right away. Especially when the
"improvements" make it harder to do simple things. I checked LO 6
on my Ubuntu 20.04 VirtualBox intstall and it seems to work OK
there (under MATE), graphic images insert properly so not sure
what gives. Maybe I hit a corner case (like immediately), maybe
it's something about this machine, but regardless of the cause the
new version didn't work and the old version works.
Had no luck getting ps2eps to work right. Uninstalled the
repository version and copied an older version from my 12.04
system to /usr/local/bin (it's just 2 files, a bbox binary and a
perl script) but it behaved the same.. rotated the vectors but not
the bounding box.. likely something changed in GhostScript that
isn't accounted for. This is a stupid simple thing people need to
do all the time (rotating PDF's), surely there's a solution, and
there is - pdftk, already installed. The following command creates
a new PDF that's rotated clockwise 90 degrees...
pdftk input.pdf cat 1-endeast output output.pdf
To rotate counter-clockwise use endwest, to flip use endsouth.
Once the rotated PDF is made then pdftops -eps can convert it to
EPS format for embedding into documentation. I'll never remember
that syntax so made 3 scripts...
-------- begin pdf2eps -------------------
#!/bin/bash # convert PDF file to an EPS file if [ "$1" = "" ];then echo "Usage: $0 input.pdf [output.eps]" echo "Converts a PDF file to an EPS file" echo "If output not specified then uses basename.eps" exit fi if ! file "$1"|grep -q "PDF";then echo "That's not a PDF file" exit fi outfile=`echo -n "$1"|head -c -4`.eps if [ "$2" != "" ];then outfile="$2";fi echo "Converting $1 to $outfile" pdftops -eps "$1" "$outfile"
-------- end pdf2eps ---------------------
-------- begin pdf2epsr ------------------
#!/bin/bash # convert PDF to a clockwise-rotated EPS file if [ "$1" = "" ];then echo "Usage: $0 input.pdf [output.eps]" echo "Converts a PDF file to a clockwise-rotated EPS file" echo "If output not specified then uses basename_rotated.eps" exit fi if ! file "$1"|grep -q "PDF";then echo "That's not a PDF file" exit fi outfile=`echo -n "$1"|head -c -4`_rotated.eps if [ "$2" != "" ];then outfile="$2";fi echo "Converting $1 to $outfile (rotated clockwise)" pdftk "$1" cat 1-endeast output /tmp/pdf2epsr.tmp.pdf pdftops -eps /tmp/pdf2epsr.tmp.pdf "$outfile" rm /tmp/pdf2epsr.tmp.pdf
-------- end pdf2epsr --------------------
-------- begin pdf2epsccr ----------------
#!/bin/bash # convert PDF to a clockwise-rotated EPS file if [ "$1" = "" ];then echo "Usage: $0 input.pdf [output.eps]" echo "Converts a PDF file to a counter-clockwise-rotated EPS file" echo "If output not specified then uses basename_ccrotated.eps" exit fi if ! file "$1"|grep -q "PDF";then echo "That's not a PDF file" exit fi outfile=`echo -n "$1"|head -c -4`_ccrotated.eps if [ "$2" != "" ];then outfile="$2";fi echo "Converting $1 to $outfile (rotated counter-clockwise)" pdftk "$1" cat 1-endwest output /tmp/pdf2epsr.tmp.pdf pdftops -eps /tmp/pdf2epsr.tmp.pdf "$outfile" rm /tmp/pdf2epsr.tmp.pdf
-------- end pdf2epsccr ------------------
If the output file isn't specified then the scripts derive it
from the input filename, "somefile.pdf" becomes
"somefile_rotated.eps". Added these to my PDF associations. Ok
back to work, see how far I get...
OK getting better
8/3/20 - Got through writing the docs and making the parts lists for the project I am working on (a Bluetooth adapter for my company's ANR headsets). LibreOffice 5.2.3 is working fine and the other tools are stepping in line. Becoming blind to Caja's cosmetic preview bugs and getting more used to the new Nautilus. Not getting used to Nautilus' more-clickity way of opening files with other associated apps, but whatever at least the overall process is getting better and the sheer speed of the new system usually makes up for the occasional UI deficiencies. My old 12.04 system can still do more, but the new system is catching up and what it can do it does much faster. While working on stuff...
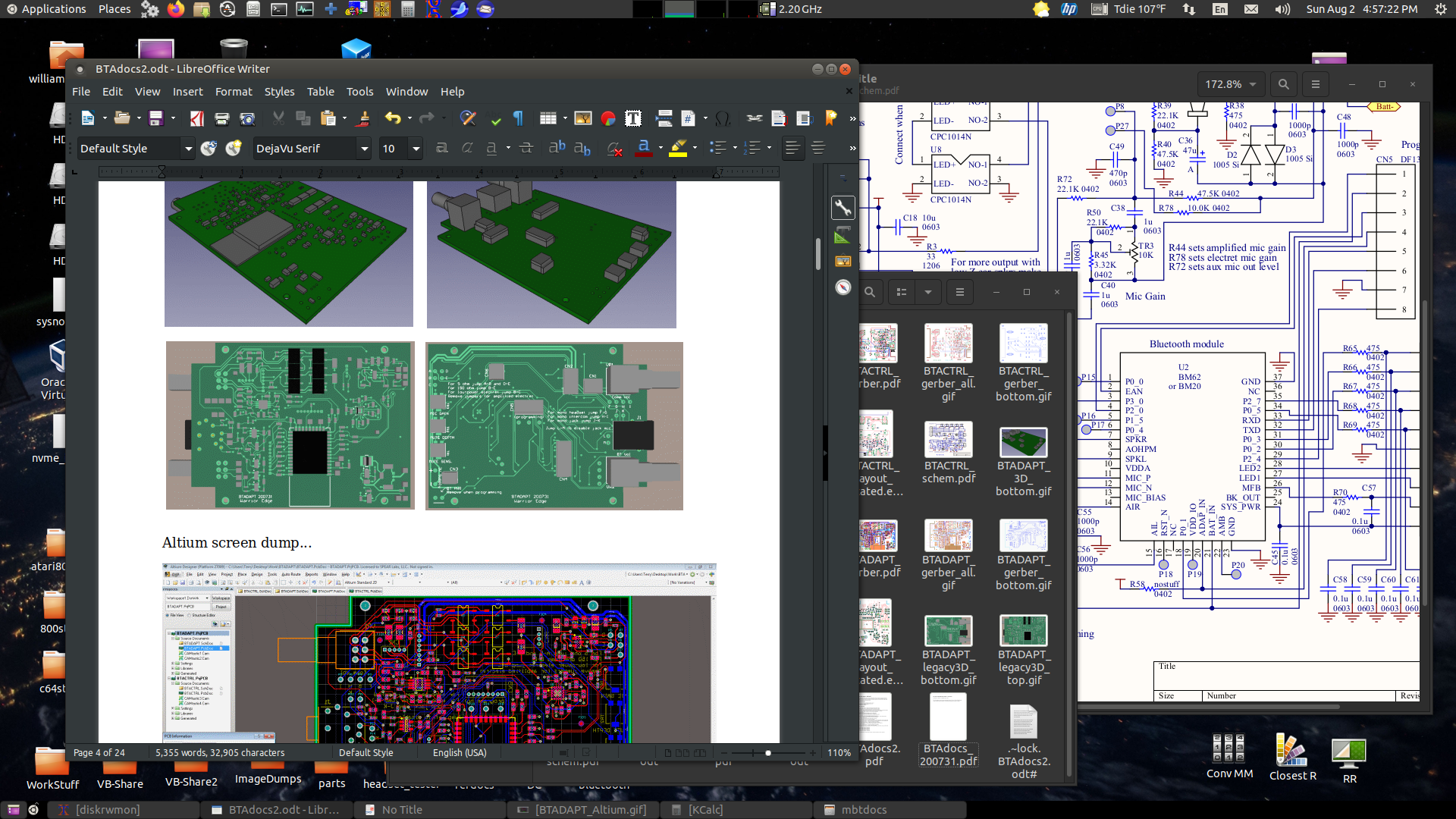
And it runs DOS... while working on stuff I needed to calculate
the output power, power dissipation and current drain of the
amplifier with various loads for the docs, so fired up QBasic and
quickly wrote the following code...
SupplyV = 4.94 'main supply voltage OpenV = 3.5 'open-circuit RMS output voltage Qcur = .005 'no-signal current drain Beta = 30 'estimated output transistor beta IntR = 13 'estimated internal output resistance SerR = 35 'external resistance in series with the load PRINT PRINT "For SerR ="; SerR; " IntR ="; IntR; " OpenV ="; OpenV; PRINT " SupplyV ="; SupplyV; " Qcur ="; Qcur; " Beta ="; Beta PRINT PRINT "LoadR", "LoadPwr(mW)", "InputPwr(mW)", PRINT "PwrDiss(mW)", "SupCurrent(ma)" PRINT "-----", "-----------", "------------", PRINT "-----------", "--------------" LoadR = 300: GOSUB calcsub: GOSUB printsub LoadR = 200: GOSUB calcsub: GOSUB printsub LoadR = 100: GOSUB calcsub: GOSUB printsub LoadR = 50: GOSUB calcsub: GOSUB printsub LoadR = 32: GOSUB calcsub: GOSUB printsub LoadR = 16: GOSUB calcsub: GOSUB printsub SYSTEM calcsub: loadpower = ((LoadR / (IntR + SerR + LoadR)) * OpenV) ^ 2 / LoadR loadcurrent = SQR(loadpower / LoadR) inputcurrent = loadcurrent + loadcurrent / Beta + Qcur inputpower = SupplyV * inputcurrent outputpower = loadcurrent ^ 2 * (SerR + LoadR) dissipation = inputpower - outputpower RETURN printsub: PRINT LoadR, loadpower * 1000, inputpower * 1000, PRINT dissipation * 1000, inputcurrent * 1000 RETURN
...which when run produced this output which I copy/pasted into
my document...
For SerR = 35 IntR = 13 OpenV = 3.5 SupplyV = 4.94 Qcur = .005 Beta = 30
LoadR LoadPwr(mW) InputPwr(mW) PwrDiss(mW) SupCurrent(ma)
----- ----------- ------------ ----------- --------------
300 30.34582 76.04004 42.15388 15.39272
200 39.83481 96.74167 49.93576 19.58333
100 55.92586 145.4185 69.91856 29.43694
50 63.77551 207.0095 98.59115 41.90476
32 61.25 248.0292 119.787 50.20833
16 47.85156 303.8615 151.3346 61.51042
I have the modern QB64 equivalent, but for whatever reason it
doesn't run this simple code and doesn't indicate why. Blassic is
good for some things like this but the extra numerical precision
is unnecessary and messes up table prints so I end up getting
bogged down writing extra code to fix stuff like that instead of
getting the numbers I need and moving on. When I'm working I don't
need complications or having to figure out why something doesn't
work, so for quick programs like this I almost always grab QBasic
first. It always works and if it doesn't it's me not it.
8/8/20 - I moved my drives back to the first new machine ZaReason
made for me, with the Gigabyte B450M DS3H motherboard. The one I
thought I blew up with an indicator light that looked like a
severely overloaded PCB trace - I still think whoever designed
that was messing with old people, had me going. The second machine
with the ASRock B450M Pro4 motherboard was OK, performance-wise
was the same but it had a tendency to run somewhat hotter. Never
overheated but Tdie would often spike to 180F+ before the fan
caught up, triggering distracting notification alarms. The
Gigabyte motherboard seems to be faster on the fan, have to push
it a lot harder to trigger a temperature notification. Running
MEVO2 set to 10 threads, 0 thread delay, evolving nano warriors...
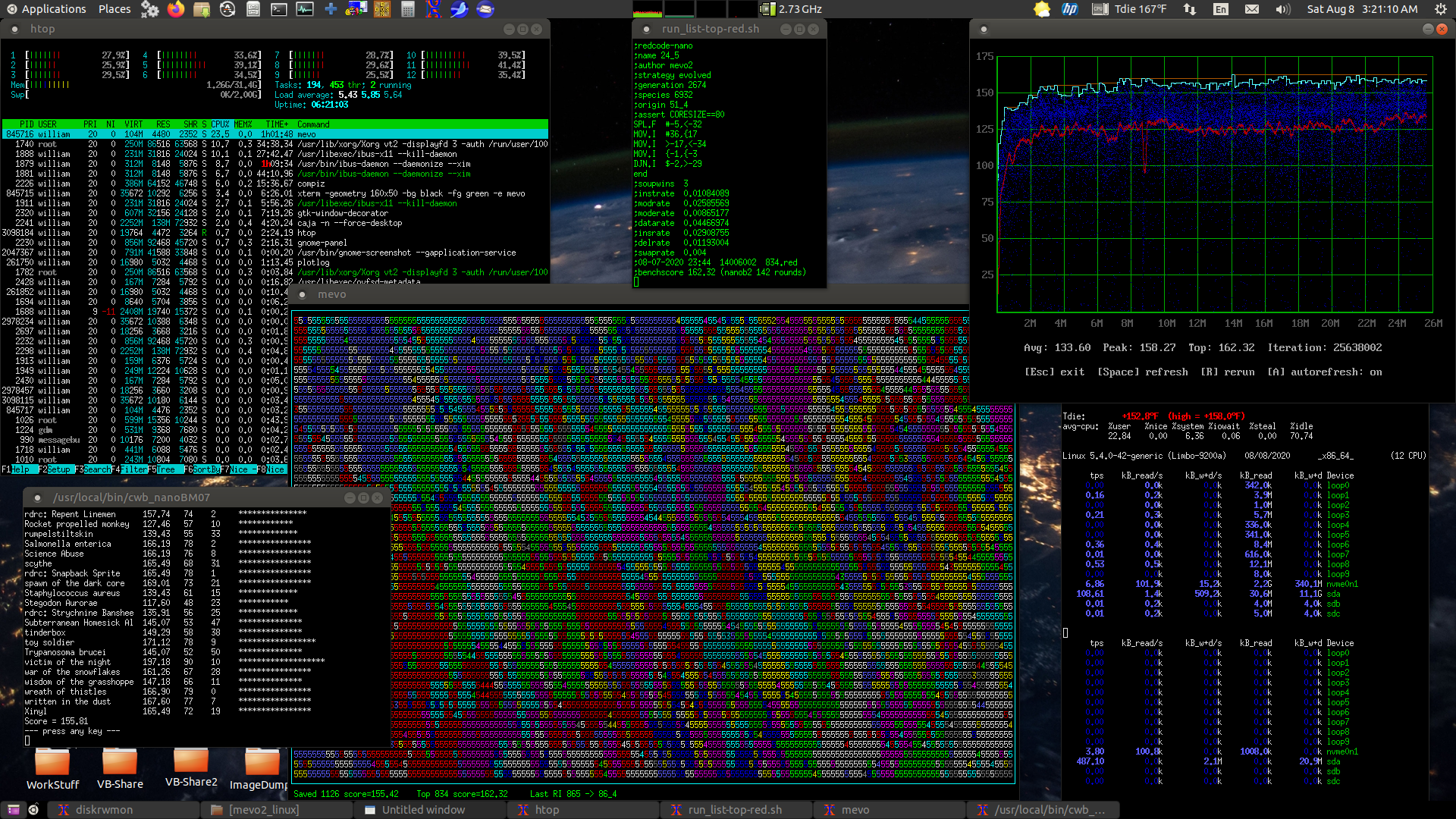
The downward drop in performance around 8.8M iterations was when
I expanded the soup from 77x21 to 158x47, generating thousands of
new unevolved warriors which were quickly displaced by the rather
strong warriors inhabiting this soup. All this is still going on
in the background as I edit this and otherwise use the system,
can't perceive any lag whatsoever.
Other reasons for making the swap back to the first machine were
the second machine has a different case with jacks on the side
instead of the front, being under my desk it put USB quantum spin
1.5 in full effect and then some. Also has a bright blue power
indicator that illuminated the whole room when on at night.. once
past the immediate work push it was time to swap back to the first
machine. The second machine has WiFi so it's better for using at
the amp shop, avoids having to run a cable for internet.
8/10/20 - This is cool...
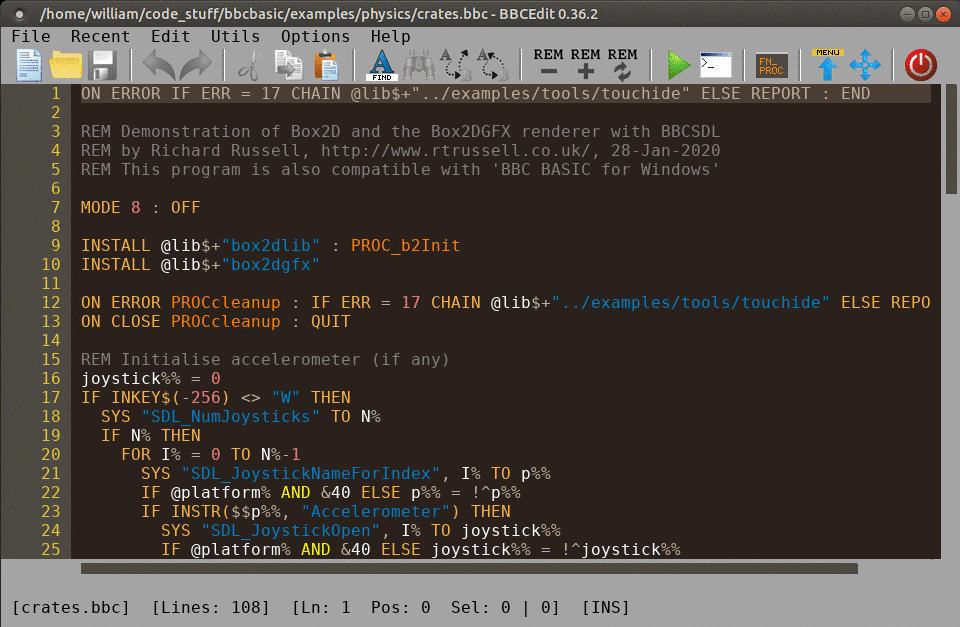
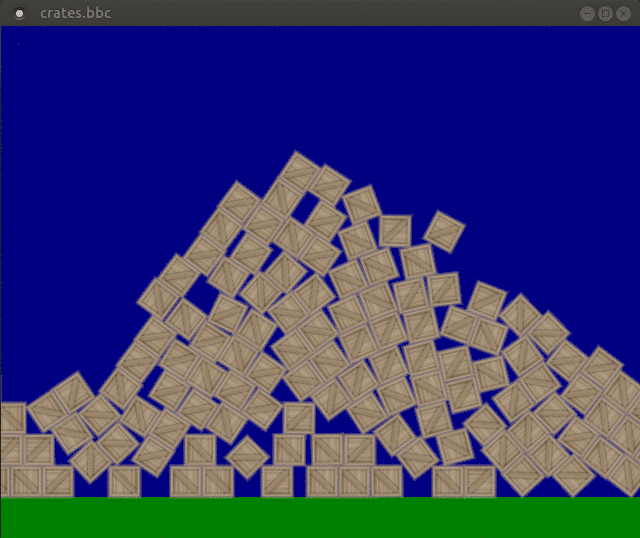
That's one of the two IDE's (integrated development environments) available with BBC Basic for SDL, the other is more like the IDE in the original Windows version. Installation is easy, extract the files to a folder somewhere, install the SDL libraries using the commands in the included text file, then run ./mkicon.sh to make a desktop short-cut. It's not exactly a compiler, but it can create stand-alone applications (using the other IDE) by making an "app bundle" which includes the program, libraries and an interpreter. The paid-for (non-SDL) Windows version works much more like a regular compiler, producing a single EXE file that can just be run. There is also a console version without graphics and sound, and a program that converts QBasic code to BBC Basic. The latter is a Windows program but it works with wine, although I had to help it a bit by creating a "lib" directory in my user's Temp directory (what to do was fairly obvious from the error message). The Windows versions of BBC Basic (regular and SDL) work fine with wine, the SDL version doesn't require installing, just unzip somewhere and run the exe. See here for the differences between the Windows and the SDL versions.
BBC Basic home pages are here and here. Also here. BBC Basic for SDL is
open source software, here's the source code.
If a command line parameter is
supplied, the SDL and console versions run the program rather than
bringing up the IDE (or the minimal interface of the console
version). To make running and associations easier I made symlinks
in /usr/local/bin to the bbcsdl and bbcbasic (console) binaries so
I wouldn't have to specify the path and if the binaries are moved
only the symlinks have to be updated.
Associating to the console version is a bit trickier as it has to
be run in a terminal and generally file manager associations don't
do that unless a desktop file or a script is made, I chose to make
a script that runs the program in an xterm terminal window...
[updated 8/17/20]
----- begin run_bbcbasic --------------
#!/bin/bash # run_bbcbasic version 200817 # this script runs a .bbc program in bbcbasic, if not already in # a terminal then launches one. Associate this script to .bbc files # to add to right-click options (usually my default is bbcsdl) # Also, to help with running bbc basic text like a script, if running # basrun2.bbc then saves cur dir to /tmp/current_bbcbasic_dir.txt # so it can preserve the directory when running the program interpreter="bbcbasic" # interpreter (full path if not on path) if [ -t 0 ];then # if running in a terminal # set terminal titlebar name to interpreter - program echo -ne "\033]2;`basename "$0"` - `basename "$1"`\a" if (echo "$1" | grep -q "basrun2.bbc") ;then # save the current working directory # basrun2.bbc has been modified to change back to the directory pwd > "/tmp/current_bbcbasic_dir.txt" fi "$interpreter" "$@" # run program in interpreter echo -ne "\033]2;\a" # clear titlebar name exit # exit script fi # if $MyRunFlag set to ran then exit if [ "$MyRunFlag" = "ran" ];then exit;fi # set MyRunFlag to keep from looping in the event of an error MyRunFlag=ran # rerun self in a terminal # uncomment only one line, modify parms as needed # profiles must have already been created, these are mine xterm -geometry 80x25 -bg black -fg green -fn 10x20 -e "$0" "$@" # gnome-terminal --profile="Reversed" -x "$0" "$@" # mate-terminal --profile="CoolTerminal" -x "$0" "$@" # konsole --profile="BBC" -e "$0" "$@"
----- end run_bbcbasic ----------------
This script runs the specified program with the bbcbasic
interpreter in an xterm terminal (if not already running in a
terminal). It also works with the tbrandy interpreter, not
specific other than the interpreter runs the program specified on
the command line.
The program has to end with QUIT to exit when the program ends,
otherwise quits to the console. The console version doesn't come
with much in the way of docs but it works pretty much like an
old-school BASIC - use line numbers so lines can be replaced,
LIST, RUN, LOAD, SAVE, NEW etc work as expected, commands must be
capitalized. Line numbers are totally optional but to edit a
program from the console then use RENUMBER, then lines can be
replaced or use EDIT line_number to edit a line. For real editing
without needing line numbers edit it using the SDL version.
The QBasic to BBC translator seems to work well except that it uses an install command for the library, so won't run outside of the Windows environment, just says file not found. To make the converted program work anywhere first make a text version of the QBLIB.BBC library (open QBLIB.BBC in the IDE then save-as, and save it as QBLIB.BAS to convert it to text form - or just copy/paste the code into a text file), then in the converted program REM out the initial INSTALL command and copy/paste the contents of QBLIB.BAS after the converted code and save.
BBC Basic is one of the most advanced BASICs I have encountered,
the graphics abilities are amazing and despite being an
interpreter the programs run extremely fast and smooth. It has its
limits and it'll take awhile to get familiar with this dialect,
but for a lot of the kinds of programs I make it should make for a
nice cross-platform programming alternative. I'm mainly using the
open source SDL version but I elected to also purchase the Windows
version, it has a better compiler function that produces a single
stand-alone EXE file with all the dependencies encapsulated
within, simplifying distribution. The Windows IDE and the exe
files it produces run more or less perfectly on my Ubuntu 20.04
system using wine, the only thing I've found that doesn't work
under wine is the help menu items and that's because wine's CHM
viewer is broken, the help files open ok using Okular or another
Linux CHM viewer [actually kchmviewer works much better]. Or use
the web manual.
Or the PDF
version.
BBC Basic
is old, the first version included with the BBC Micro was
released around 1982. Most of the original code was written by
Sophie Wilson (who also invented the ARM processor architecture),
more recent development (the last few decades) has been mostly by
Richard Russell, who created Z80, MSDOS and other ports and
presently maintains the Windows, SDL and console versions. Being
an old language also means it is fairly stable, while there are
differences between the various platforms and sometimes changes in
the computing environment necessitate changes in low-level code,
but by and large the language isn't going to change - I like that!
Why I still use QBasic. Most of the updates now are bug fixes, and
it's open-source so if I need to I can fix stuff myself. Getting
it to compile was fairly easy, just had to install nasm
libsdl2-net-dev and libsdl2-ttf-dev in addition to the
libsdl2-ttf-2.0-0 and libsdl2-net-2.0-0 I had to install to use
the binary version. Already had the main libsdl2 and dev packages.
Basically (as usual with these things) kept running make and
installing what it complained about until it stopped complaining.
One oddity - the binary isn't recognized as a binary by file
managers etc, the type comes back as "ELF 64-bit LSB shared
object", whereas most Linux binaries are type "ELF 64-bit LSB
executable". Still runs fine from scripts, desktop files,
associations or a command line, just can't double-click a BBC
Basic binary directly from the file manager (at least not from
Nautilus or Caja).
Here are a few things I found on the net...
The Usborne books are supposed to be for kids, but they'll also
turn an aging man back into a kid.. I guess '20's count. Back to
the days of typing in programs and saving them on cassette tape.
When I got a C64 with an actual disk drive, now that was
something. Still have a lot of those programs I used to play
with.. Elite was one of my favorites. Nowadays when my computer
writes only a billion bytes to my solid state disk that's a light
usage day.
8/11/20 - here's a script that can be associated to .bbc files to
edit them using the SDLIDE.bbc editor...
----- begin edit_SDLIDE --------------
#!/bin/bash # edit a BBC program using the SDLIDE.bbc editor editfile=$(readlink -f "$1") sdlide=$(dirname $(readlink -f $(which bbcsdl)))/examples/tools/SDLIDE.bbc bbcsdl "$sdlide" "$editfile"
----- end edit SDLIDE ----------------
The script requires a symlink to the bbcsdl binary in a path
directory such as /usr/local/bin, it figures out where the bbcsdl
install directory is from the symlink using the which, readlink
and dirname commands. There is one program that can't be edited -
SDLIDE.bbc - editing the editor from itself would just be silly,
not to mention risky. If you must do that (even just to see the
code) then edit a copy.
The SDLIDE editor is turning out to be quite nice...
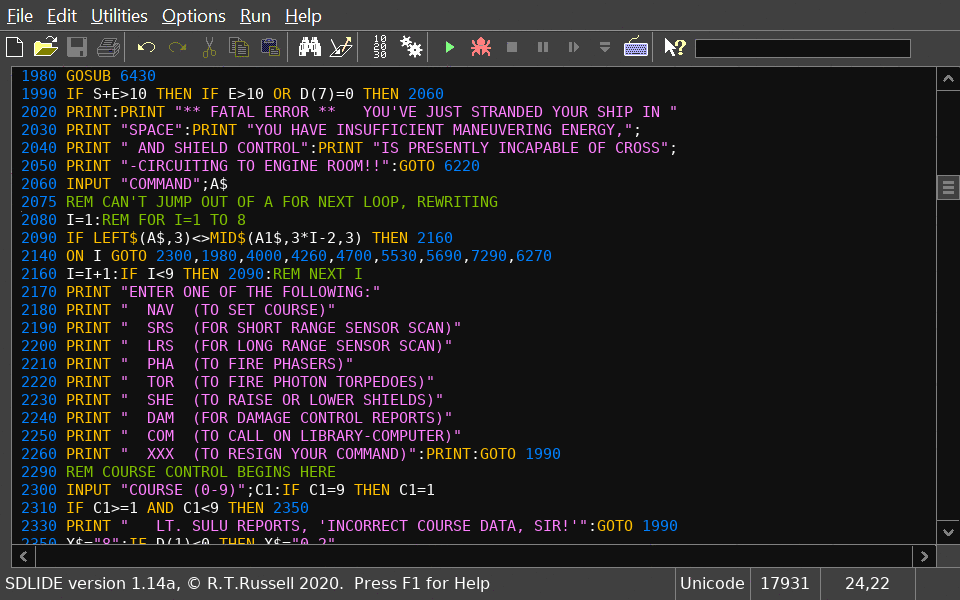
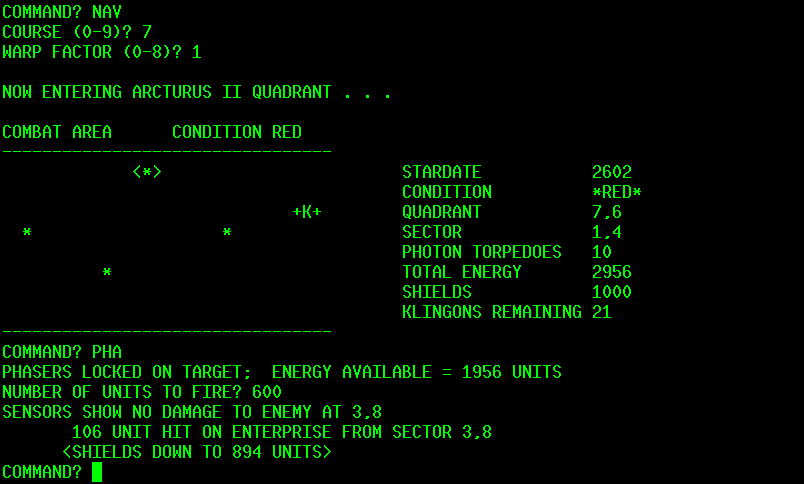
I can run the code from the IDE but with my run_bbcbasic script I
can right-click the .bbc file and run it in a terminal using the
console version for a more retro look... (which also lets me
copy/paste the program output)
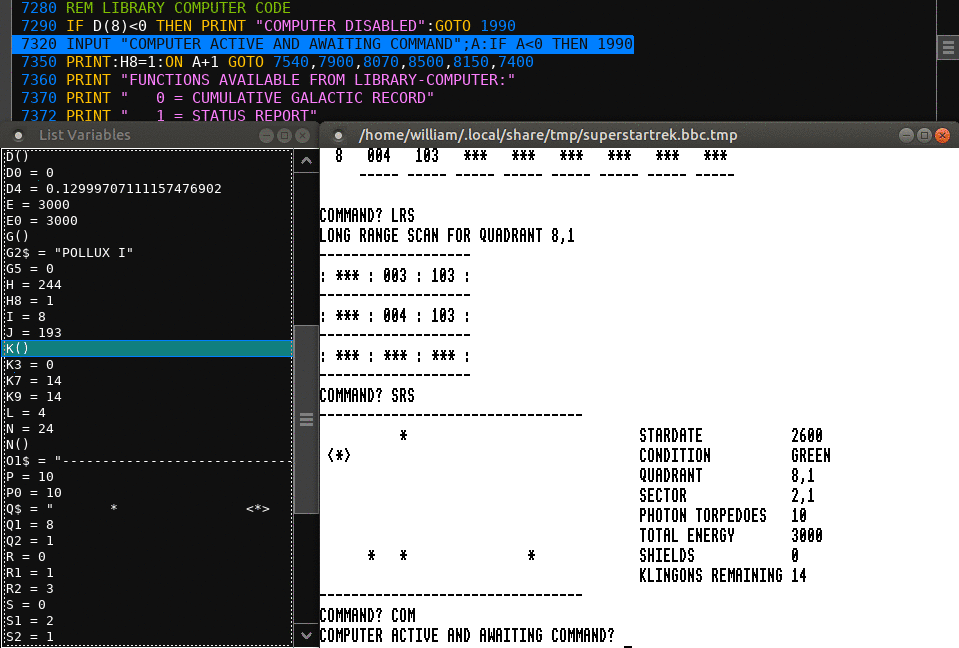
SDLIDE isn't quite as colorful as BBCEdit but besides the huge
advantage of being able to script it for right-click editing, it
has a really nice debugging facility that shows the execution
point and the contents of variables...
Despite the advanced features, for the most part that can be
ignored for running old-school BASIC code.. I didn't have to do
that much to get the MS BASIC version of the old
"superstartrek.bas" program running - added spaces between the
keywords (BBC Basic tolerates some scrunching but sometimes it
conflicts with new keywords), changed the number prints to add
surrounding spaces and added a string before prints that started
with a number to avoid unwanted tabbing, and most importantly,
rewrote any FOR/NEXT loops with code that jumped outside the
loop.. could get away with that with some early BASICs but not
with BBC Basic and most other modern BASICs which keep the loop
variable on the stack. Easy enough to replace code like...
[example edited to clarify scope]
1200 FOR I=1 TO 7:FOR J=2 TO 9 1210 X=A(I,J):IF X=9 THEN 2000 1220 NEXT J:NEXT I 1230 REM CODE 2000 REM DISTANT CODE
...with something like...
1200 I=1 1202 J=2 1210 X=A(I,J):IF X=9 THEN 2000 1220 J=J+1:IF J<=9 THEN 1210 1222 I=I+1:IF I<=7 THEN 1202 1230 REM CODE 2000 REM DISTANT CODE
It gets a little trickier when the loop terminator is a variable
and that variable is modified during the loop, have to figure out
if it goes by the initial value, or the value when next is
executed. I always considered that undefined behavior that depends
on the implementation.
8/12/20 - In the original FOR/NEXT mod example the jump was to right after the loop, BBC Basic has a command just for that - EXIT FOR [var]. EXIT FOR exits the current FOR/NEXT, EXIT FOR I would exit all loops until it exits the FOR I loop. Also has similar commands for REPEAT and WHILE loops. Most languages have similar constructs for exiting loops, sometimes just have to leave a loop early. However, these constructs are of little use when converting old code that contains numerous jumps out of loops to destinations throughout the program, so needed a conversion method that just worked and could be applied without much thought about what the code actually did. Edited the example to make that use case more clear. There were a few other things that needed fixing.. early MS BASIC dropped through if ON var GOTO was out of range, in BBC Basic this is an error so needed a bit of code to make sure the variable has a valid target.
The Super Star Trek conversion seems to be fairly stable now so here's the code, will update it if I
find any major bugs. I modified the look of the short range scan..
the original had no divisions making it more difficult to figure
out directions. Here's how it looks now...
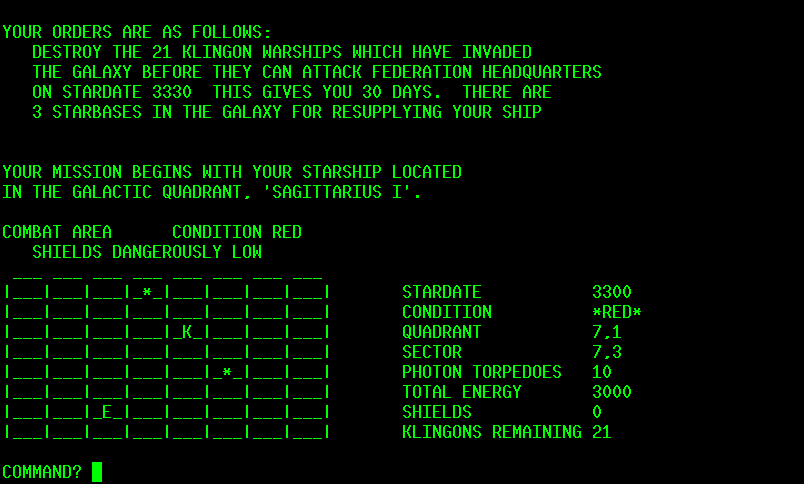
The stock look can be restored by changing a few variables near
the beginning of the program.
The Star Trek program (and its many versions) is one of my
favorite bits of old code to play around with, for comparison here
are versions for Atari 8-bit
and for a HP21xx minicomputer.
This conversion was fairly trivial compared to those, at least in
its current form. It is tempting to try a graphical conversion...
would be a good opportunity to learn about graphics and text
viewports and all that stuff. The Atari version, although still
text-based, used screen codes to keep the short range scan visible
all the time, at least when not damaged.
10/17/20 - Made a few minor mods to the Star Trek code so make
the input prompts consistent between different versions of BBC
Basic. Also modified the computer so that enter or 0 brings up a
list of commands, reject invalid inputs (before could crash with
divide by 0) and to display distance in both navigation units and
the actual distance (which is used only for phasor strength
calculations). See below for discussion about INPUT
behavior.
2/9/21 - A colorized version of the
Star Trek program... [under development, now has difficulty level,
save/restore and preference settings]
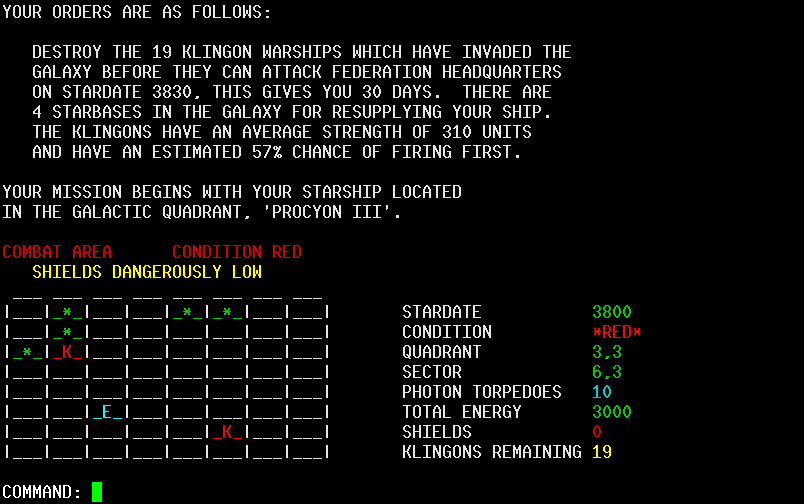
...makes it look better when playing it on my phone using the
Android version of BBC Basic (downloaded from this page).
To make it show up under @usr$ in the BBC Basic Android app, I
copied the program (after converting to .bbc format using the PC
IDE) to the phone's Android/data/com.rtrussell.bbcbasic/files/
folder. Still figuring out the Android version but it's pretty
darn neat. [...]
2/11/21 - After a few days of playing around with it I'm learning
more about how to use the setup.. doing anything PC-like on a
phone is different (to put it mildly). The system boots into
"TouchIDE" (touchide.bbc) which permits browsing the file system
for .bbc programs, @lib$ and @usr$ are always available.. @usr$
goes the PC-accessible directory, @lib$ goes to the library
directory and provides an easy way to get back "home", from @lib$
tap .. to go to the default immediate mode load/save area and from
there tapping examples goes to the startup directory. Holding a
file brings up options to edit, delete, rename, copy and cut. Copy
and cut permits copying and moving files (for moving it's safer to
copy then come back and delete the original). Holding empty space
past the file list brings up options for new file, new folder,
paste, list all files and exit. The editor has zooming and syntax
hi-lighting, nice! Prompts to save when exiting via the back
button. Most of the sample programs return to TouchIDE when back
is tapped (on my buttonless phone I have to swipe up to get
buttons), but it's trickier for simple programs that aren't aware
of the environment. On my phone once the keyboard disappears
(after pressing back twice to trigger Esc to interrupt a program)
it's hard to get it back, but with determined quick tapping I can
get it back (getting better at it.. too bad Esc isn't on the
phone's virtual keyboard). Ignoring cheap phone glitches, I'm
impressed! This is a full-blown BBC Basic programming
environment.. on a phone!
2/15/21 - [separate Android version removed, it's now all in the
main SST3 program] There are a few tricks to programming with the
Android version, mostly because of the strangeness of Android
itself. While files can be copied from a PC to the directory
referenced by @usr$, copying edited files there (even with the
phone's file manager) don't show up when the phone is mounted on
my PC (ugh why? to make it harder to back up my files?). The only
way I found to get files back out of the phone was to copy them to
a SD card, then the files show up when mounted. Android is
peculiar...
Matrix Brandy
8/14/20 - Matrix Brandy is a fork of the Brandy BBC Basic interpreter that adds SDL 1.2 graphics support, among things. The language isn't as complete as BBC Basic for SDL2 and it doesn't have an IDE, but it has a couple of properties that makes it particularly useful for Linux users - it can load and run basic code in (unix) text format from the command line, and if the first line starts with #! then it treats that line as a comment. These properties permit adding a #! line to the beginning of a program to specify the interpreter, making it executable, then running it as if it were any other program. For example adding "#!/usr/local/bin/brandy" (without the quotes) as the first line makes it run in a graphical environment when double-clicked (in Ubuntu it asks whether to run, display or run in a terminal). There is also a console version called tbrandy for text-only programs, adding a line like "#!/usr/bin/env -S konsole --profile="BBC" -e tbrandy" makes it use tbrandy to run the code in a konsole terminal using the (previously created) profile "BBC". Or can copy of the run_bbcbasic script presented earlier to run_tbrandy and edit it to use tbrandy instead of bbcbasic, then specify #!/usr/local/bin/run_tbrandy on the first line - then if just run is selected it runs the program in the terminal specified in the script and if run in terminal is specified it runs it in the system default terminal. Choices! All these examples assume that symlinks to the binaries and scripts are in the /usr/local/bin directory, the usual place for those things.
Matrix Brandy must be compiled from source, it's not difficult
but have to have build-essential installed along with -dev
packages for SDL 1.2 and other packages, when compiling the error
messages will say what is missing, search for the corresponding
-dev packages in Synaptic or another package manager. The tbrandy
(and sbrandy) console versions have far fewer dependencies.
Building both the graphical and console versions in the same
directory is slightly tricky, make clean has to be run before
recompiling to remove previously compiled objects or it's a shower
of errors.. this also (sometimes) has the effect of removing the
binaries so previously compiled binaries have to be preserved. To
make it easier I just threw it all into a script...
----- begin makeall.sh -----------------
#!/bin/bash # rebuild all versions # remove existing executables rm brandy rm sbrandy rm tbrandy # build sbrandy and tbrandy echo echo "Building sbrandy and tbrandy" echo make clean make text # rename binaries to preserve # (current make clean doesn't delete these but might in the future) mv sbrandy sbrandy_ mv tbrandy tbrandy_ # build SDL version echo echo "Building brandy" echo make clean make # preserve binaries mv brandy brandy_ # clean up make clean # restore binaries mv sbrandy_ sbrandy mv tbrandy_ tbrandy mv brandy_ brandy # pause so any errors can be read sleep 5
----- end makeall.sh -------------------
Being able to run BASIC code like a script is very useful for
simple programs and quick "one off" hacks. Previously I have used
(and still use) blassic for that, and made "fbcscript" which takes
a program, strips out the first #! line, compiles the rest with
the fbc (FreeBasic) compiler then runs it. Neither solution is
optimal. Blassic is way out of date and barely functions these
days (immediate mode is broken, still works in #! mode but who
knows for how long), fbcscript works but is somewhat fragile,
there's a delay while compiling and it makes temp files. Something
that's reasonably up to date and just works is much preferable,
and since its purpose is mainly for quick hacks I don't care if
the language doesn't have advanced features... if it can take
input, calculate, print results and read and write files I'm
pretty much good, don't need much more than that for use as a
script language.
Using BBC BASIC as a script language
8/17/20 - The BBC Basic SDL and console interpreters can also be
used for making script-like programs, although it is not as
straightforward as it is with a program that was designed to be
scriptable. Modifying BBC Basic itself to be compatible with Linux
scripting would be very difficult, and wouldn't be the right thing
to do even if it could be done because it could impact existing
program code. Rather, if doing such a thing, it should be done
using external scripts. The piece of code that really makes it
possible is Richard Russell's basrun.bbc
program loader. With some mods I was able to run BBC Basic
code in (unix format) text form by adding a #! line to the
beginning of the program. There were still some issues to work
out.. preserving the current directory and adapting to how SDL
treats file names without an extension (it changes "file" to
"file.dat" and changes "file." to "file" - that's just nutty in my
opinion).. but it all seems to be working ok now.
This presently requires the run_bbcbasic script (presented earlier on this page) to properly set
the working directory when running a program from the command
line. To set it all up, first of all there should be a symbolic
link to or a copy of the bbcbasic binary in /usr/local/bin so that
it can be run by simply bbcbasic instead of having to specify the
path. A symbolic link might be better since then the @lib$ string
will be correctly set to the library directory, but for programs
that don't load library code it doesn't matter. To make a copy to
/usr/local/bin, open a terminal where the bbcbasic binary is at
and enter "sudo cp bbcbasic /usr/local/bin" (without the quotes).
To make a symlink, enter "sudo ln -s -t /usr/local/bin $(readlink
-f bbcbasic)" instead. When using similar tricks for the graphical
bbcsdl program it has to be a symbolic link or programs like the
SDLIDE editor won't work.
If it doesn't already exist create a directory named "bbcbasic"
in your home directory, create a file there called "run_bbcbasic",
open it in a text editor, copy the run_bbcbasic code into it and
save. Right click the run_bbcbasic file and under permissions
check the box to allow executing as a program. Next, fire up the
bbcsdl code editor and copy the basrun2.bbc code below into the
editor and save it to "basrun2.bbc" in the bbcbasic directory
(where run_bbcbasic is).
As written the run_bbcbasic script requires xterm when it detects
that it's not running in a terminal, so either install the xterm
package, edit the run_bbcbasic script to make it use another
terminal that you have, or when double-clicking scripts select
"Run in terminal" instead of just "Run".
With these files it will work using a #! line like
"#!/usr/bin/env -S ${HOME}/bbcbasic/run_bbcbasic
${HOME}/bbcbasic/basrun2.bbc" but that's a whole lot of error
prone typing so let's simpify. Create a file called "bbcscript"
and copy the following code into it...
----- begin bbcscript -----------
#!/bin/bash # run basrun2.bbc with run_bbcbasic passing all parms "$HOME/bbcbasic/run_bbcbasic" "$HOME/bbcbasic/basrun2.bbc" "$@"
----- end bbcscript -------------
...make the file executable and copy it to /usr/local/bin (sudo
cp bbcscript /usr/local/bin). Or can be anywhere, that's just the
usual place for things like this.
----- begin ScriptTest -----
#!/usr/local/bin/bbcscript code=INKEY(-256) PRINT "Code = ";INKEY(-256) IF code=115 THEN PRINT "Platform = ";@platform% PRINT "Current directory: "; : *CD PRINT "Program directory: "; @dir$ PRINT "Library directory: "; @lib$ PRINT "User directory: "; @usr$ PRINT "Temp directory: "; @tmp$ t1=INSTR(@cmd$," "):t2=INSTR(@cmd$," ",t1+1) parms$="":IF t2>0 THEN parms$=MID$(@cmd$,t2+1) prog$=MID$(@cmd$,t1+1):IF t2>0 THEN prog$=MID$(@cmd$,t1+1,t2-t1) t1=0:t2=1:WHILE t2<>0 t2=INSTR(prog$,"/",t1+1):IF t2<>0 THEN t1=t2 ENDWHILE:progdir$="":IF t1>0 THEN progdir$=LEFT$(prog$,t1-1) PRINT "progdir from file: "; progdir$ PRINT "Extra parms after 2nd: "; parms$ PRINT "@cmd$ = ";@cmd$ PRINT INPUT "Press enter to exit " a$ QUIT
----- end ScriptTest -------
...make the file executable, and you should be able to
double-click the program to run it.
Here's the modified basrun2.bbc code. This is a work in progress.
See the discussion following the listing.
----- begin basrun2.bbc (copy to IDE and save) ------------
REM basrun2.bbc - use bbcbasic as a script interpreter for Linux - version 200817B REM This code is based on code from the BBC Basic Wiki REM https://www.bbcbasic.co.uk/wiki/doku.php?id=running_a_bas_file_from_the_command_prompt REM Modified to allow running basic code using an initial #! line, for example REM #!/usr/bin/env -S run_bbcbasic /path/to/basrun2.bbc REM ...basic code... REM run_bbcbasic assumed to be in a path dir, i.e /usr/local/bin REM Can simplify the #! line by using another script that runs the full #! line. REM The run_bbcbasic (or another) script writes the current directory REM to "current_bbcbasic_dir.txt" in the tmp directory (/tmp/ for console REM version, $HOME/.local/share/tmp/ for bbcsdl), if the file exists REM this loader changes to the directory specified in the file then removes the file. REM This mechanism permits running programs from a command line and preserving the REM current directory. If the current_bbcbasic_dir.txt file does not exist, then if REM the file path is specified and under /home/ then it changes to that directory REM setup variables for files and behavior switches REM path and name of file to read for changing directory curdirfile$=@tmp$+"/current_bbcbasic_dir.txt" REM if not 0 try short filename first, if 0 try long filename first REM side effects if try short first then if program is "some file" and "some" REM exists then will open "some" instead. If 0 then if double-clicked then REM "some file" runs, but from the command line using parms then running REM ./some file will instead run "some file" if it exists. Pick your bug. tryshortfirst=0 REM for files with no extension, if not 0 also try without trailing dot REM (apparently) SDL opens "file.dat" if "file" specified and "file." opens "file". REM if that behavior changes, make 1 to also try "file" instead of "file." trywithoutdot=0 REM for when curdirfile$ isn't found, if not 0 change to program file path REM if 0 and curdir$="" then remain wherever basrun2.bbc is located cdtoprogpath=1 REM. Find address of string accumulator: IF INKEY(-256)<>&57 IF @platform% AND &40 Accs%% = ]332 ELSE Accs%% = !332 REM. Allocate a 256-byte string buffer: DIM Buff%% 255 REM. Find BAS file name: IF ASC@cmd$=&22 P% = INSTR(@cmd$,"""",2) ELSE P% = INSTR(@cmd$," ",2) IF P% = 0 ERROR 0, "No BAS filename specified" REM get filename and fix file$ = MID$(@cmd$,P%+1) IF tryshortfirst THEN REM truncate file$ after next space if present t = INSTR(file$," "):IF t THEN file$=LEFT$(file$,t-1) ENDIF REM If no extension add "." to the end of the filename REM This is an SDL file thing, if there is no extension then it REM converts "file" to "file.dat" and converts "file." to "file" REM don't be fooled by paths or ./prog so parse after last "/" if any pos = 0 : t = 1 WHILE t t = INSTR(file$,"/",pos+1) IF t <> 0 THEN pos=t ENDWHILE IF INSTR(file$,".",pos+1) = 0 THEN file$=file$+"." REM default bbcbasic/bbcsdl changes the directory to where a .bbc file is REM for script or command line usage that doesn't work so run_bbcbasic REM and other scripts are coded to write the current dir to a file curdir$ = "" cdfile = OPENIN (curdirfile$) IF cdfile <> 0 THEN curdir$ = GET$#cdfile IF LEFT$(curdir$,1) <> "/" THEN curdir$ = "" ENDIF CLOSE #cdfile IF curdir$ <> "" THEN OSCLI "cd """+curdir$+"""" REM remove current dir file if it existed so it won't affect other progs IF cdfile <> 0 THEN OSCLI "rm """+curdirfile$+"""" REM Open BAS file: F%=OPENIN(file$) IF trywithoutdot>0 AND F%=0 AND RIGHT$(file$,1)="." THEN REM try it without the added "." F%=OPENIN(LEFT$(file$,LEN(file$)-1)) ENDIF IF F%=0 THEN REM try different combinations until something works or it fails temp$=MID$(@cmd$,P%+1):q=INSTR(temp$," "):file$=temp$ WHILE q>0 AND F%=0 pos=0:t=1:WHILE t<>0:t=INSTR(file$,"/",pos+1):IF t<>0 THEN pos=t ENDWHILE:IF INSTR(file$,".",pos+1)=0 THEN file$=file$+"." F%=OPENIN(file$) IF trywithoutdot>0 AND F%=0 AND RIGHT$(file$,1)="." THEN F%=OPENIN(LEFT$(file$,LEN(file$)-1)) ENDIF IF F%=0 THEN q=INSTR(temp$," ",q+1):IF q>0 THEN file$=LEFT$(temp$,q-1) ENDWHILE ENDIF IF F% = 0 ERROR 0, "Couldn't open file " + file$ IF cdtoprogpath THEN REM found the file now fix for the case of double-clicking, if the filename REM is fully specified and under /home/ then change to the program's directory REM if run from anywhere else (path etc) then remain in this directory REM Only do this if curdir$ is empty, meaning it did not already change dir IF curdir$ = "" AND LEFT$(file$,6) = "/home/" THEN REM still have pos indicating the last / so use it curdir$ = LEFT$(file$,pos-1) OSCLI "cd """+curdir$+"""" ENDIF ENDIF REM. Allocate space for program: DIM Prog%% EXT#F% + 255 Prog%% = (Prog%% + 255) AND -256 PAGE = Prog%% REM ignore the first line if it starts with #! $Buff%% = GET$#F% IF LEFT$($Buff%%,2) <> "#!" THEN REM not a script so close the file and reopen REM same file same time so allocation remains valid CLOSE #F% : F% = OPENIN (file$) IF trywithoutdot>0 AND F%=0 AND RIGHT$(file$,1)="." THEN F%=OPENIN(LEFT$(file$,LEN(file$)-1)) ENDIF ENDIF REM. Read and tokenise BAS file: WHILE NOT EOF#F% $Buff%% = GET$#F% IF $Buff%%<>"" THEN N% = VAL$Buff%% WHILE ?Buff%%=&20 OR ?Buff%%>=&30 AND ?Buff%%<=&39 $Buff%% = MID$($Buff%%,2) : ENDWHILE REPEAT I%=INSTR($Buff%%,".") : IF I% MID$($Buff%%,I%,1) = CHR$17 UNTIL I%=0 : REPEAT I%=INSTR($Buff%%,"\") : IF I% MID$($Buff%%,I%,1) = CHR$18 UNTIL I%=0 : IF EVAL("1RECTANGLERECTANGLE:"+$Buff%%) $Buff%% = $(Accs%%+4) REPEAT I%=INSTR($Buff%%,CHR$18) : IF I% MID$($Buff%%,I%,1) = "\" UNTIL I%=0 : REPEAT I%=INSTR($Buff%%,CHR$17) : IF I% MID$($Buff%%,I%,1) = "." UNTIL I%=0 : L% = LEN$Buff%% + 4 : IF L%>255 ERROR 0, "Line too long" $Prog%% = CHR$(L%)+CHR$(N%MOD256)+CHR$(N%DIV256)+$Buff%% : Prog%% += L% : ?Prog%% = 0 ENDIF ENDWHILE CLOSE #F% : !Prog%% = &FFFF00 F% = 0 : I% = 0 : L% = 0 : N% = 0 : P% = 0 : RUN
----- end basrun2.bbc -------------------------------------
[edits for the 200817B version]
When using with the bbcbasic console version, this requires the
run_bbcbasic script (version 200817 or later) to properly set the
current directory so that files can be executed normally from a
command line. I changed the location of the
"current_bbcbasic_dir.txt" temp file to the @tmp$ directory, which
for bbcbasic consol is "/tmp/" and for bbcsdl is
"$HOME/.local/share/tmp".
For graphical programs the following script can be put in /usr/local/bin to run in bbcsdl from a #!/usr/local/bin/bbcsdlscript line...
----- begin bbcsdlscript --------
#!/bin/bash # run basrun2.bbc with bbcsdl passing all parms # a symlink to bbcsdl must be in a path dir such as /usr/local/bin # saves current dir to file so basrun2.bbc can restore it cdfiledir="$HOME/.local/share/tmp" mkdir -p "$cdfiledir" pwd > "$cdfiledir/current_bbcbasic_dir.txt" bbcsdl "$HOME/bbcbasic/basrun2.bbc" "$@"
----- end bbcsdlscript ----------
This makes use of the dir changing facility in basrun2.bbc so
that programs will run normally from a command line.
For a graphical program that should start in the directory the program is in, even if ran from somewhere else (say to be able to find its files), then use something like...
#!/usr/bin/env -S bbcsdl ${HOME}/bbcbasic/basrun2.bbc
REM basic code
...assumes a symlink to bbcsdl in a path dir, and basrun2.bbc is
in $HOME/bbcbasic/. This won't work from a command line running a
program directly using say "./filename" because the path supplied
by the #! mechanism won't be complete and it won't be able to find
itself. The full path is supplied to the #! line only when
double-clicking, the program is in a path dir such as
/usr/local/bin when it was run from a command line, or the program
was run from a file manager's Scripts directory.
My modified basrun2.bbc loader now works for most of the
situations where I would want to run a BBC Basic program as a
script. It's not perfect and probably can't be due to how BBC
Basic's @cmd$ variable works. On a Linux system, quotes around
file names and other items are there only to group parameters into
the argv$(n) slots and all quotes are removed before passing the
parameters to the program. At least if not escaped but escaped
quotes don't group parameters. I'm not sure but it appears from
looking at the original basrun.bbc code that Windows leaves the
quotes on the command line and probably ignores them when opening
files. Linux certainly doesn't, in Linux a quote is a valid
filename character and to be avoided as it seriously messes up the
shell's quoting mechanism (thus the shell removes them).
The current implementation of BBC Basic's @cmd$ variable works
fine for what it is.. internally BBC Basic uses argc/argv to open
and run the initial file, so no problems with long file names
there, and passes everything else to the program as-is, quotes or
not, the program has to figure it out. It's not hard, a program
runs the same under Linux or Windows if it skips to the first
space, or if the first character is a quote, then skip to after
the space after the next quote. Same as the basrun code does. When
running from a #! line it's even simpler, don't have to parse
quotes and scripts almost always have no spaces in the filename so
just have to skip two spaces. If a script expects a single
filename (the most common use case) then it doesn't matter if the
filename has spaces or not, just treat everything after the second
space as a filename and open it.
Where things get tricky is when the script program itself has
spaces in its file or path name, there is no good way to
distinguish between the program filename and the parameters. The
approach I took is to assume that for command line or
file-processing scripts the script filename will have no spaces
and any filename passed to it that might include spaces will be
the last parm. For programs with spaces in the script name just
run them and don't worry about it, generally such a program won't
be taking parameters anyway. So the loader tries every combination
it can until either it opens a file (hopefully the program) or
fails. The tryshortfirst switch near the beginning determines if
it tries the shortest filename possibility first, or starts with
the full command line (after the /path/to/basrun.bbc part). Either
approach has cases where it doesn't work but for most cases either
will work.
My main use case is simply convenience.. just downloaded some BBC
Basic code, want to run it so load it into an editor, add a #!
line, set it to executable and double-click it. I can edit and
process the code with the tools I'm used to and I don't have to
maintain it in both text and bbc format. If I want I can rename it
to .bas and still edit it using SDLIDE, then rename it back and
reconvert it back to unix line ends. Matrix Brandy already works
that way but programs for Matrix Brandy and BBC Basic are often
different. Another use case is making trivial calculating or file
processing programs.. fire up an editor, write some code, make it
executable and run it - instant app. Whether or not I use Matrix
Brandy or BBC Basic depends on what I'm doing. One silly reason I
like BBC Basic is its INPUT prompt adds a space, Brandy's doesn't
and then I'm inclined to write extra code because, well just
because I like it that way. On the other hand if I needed a script
that needs advanced command line processing then I would use
Brandy because it has argc/argv type parameters. Most of the time
I only need simple parameters like for a filename or no parameters
at all and for that BBC Basic works fine.
A bit over a week ago I was stuck with using blassic and my
FreeBasic hack for stuff like this, neither of which worked that
well. Now I have two good choices, plus two full IDE's for more
sophisticated stuff. Definitely worth a week of part-time hacking.
BBC Basic Source Code
Highlighting
8/18/20 - Here's a bbcbasic.lang
file (zipped) [updated 4/6/21] for syntax highlighting BBC
Basic and other BASIC code when editing in Gnome's Gedit or Mate's
Pluma text editors. To use, create the directories
"gtksourceview-3.0/language-specs" and
"gtksourceview-4/language-specs" under your ".local/share"
directory and copy the bbcbasic.lang file to both of them. Gedit
uses the GTK 4 folder, Pluma uses the GTK 3 folder. After
installing there should be a BBCbasic entry for the available
languages. It's "globbed" to *.bas files so once set all .bas
files should colorize when editing, edit as needed. The colors
depend on the editor theme, here's what it looks like on my system
using the Cobalt theme...
(here's the BaCon language file it
was derived from, also one for
FreeBasic that might be useful)
10/17/20 - The INPUT command in BBCSDL and BBC BASIC for Windows
behaves slightly differently than it does in Brandy and the
original (emulated by BeebEm) Acorn BBC - by default
BBCSDL/Windows adds a space after the ? prompt, and the originals
do not. Personally I prefer the default space since that's almost
always what I want and it better matches other modern BASICs, but
it does make programs behave slightly differently depending on the
interpreter. The fix is easy, instead of say...
INPUT "Command",A$
...instead do...
INPUT "Command? "A$
...without the separator between the quote and variable, then it
looks the same on other interpreters that may or may not add the
extra space and allows specifying a prompt besides a question
mark.
Running programs by association
When it comes to associations Windows users have it fairly easy,
it mostly goes by the file extension (I primarily use Windows 7
for work stuff and have only dabbled a bit with 10, so I don't
know if that's changed). Associations in Linux, on the other hand,
are tricky, Linux can go by file extensions (which is how I use
associations) but internally goes by the "mime" file type and can
make associations based on file contents, regardless of the
extension. A text file is still a text file no matter how it's
named. It used to be fairly easy to create new file types and
associate apps with file types but somewhere along the way it got
harder - the consensus seemed to be associations should be done by
the apps themselves and not by users - bah. It's almost impossible
to find a utility that can create new file types, and many file
managers can only associate a program that has a corresponding
.desktop file to define the running environment (terminal or not
etc). MATE's Caja file manager is an exception, it permits
associating file types directly to a command.
To compensate for the lack of association tools, I created a
couple of scripts, they're on my previous Ubuntu
Stuff page, for convenience listing them again here.
Warning! Use With Care! If misused these can mess up existing
associations, particularly AddToFileTypes. The changes made by
AddToFileTypes can be undone by rerunning and leaving the type
name field blank and confirming.
------- begin AddToFileTypes -----------------
#!/bin/bash # AddToFileTypes script for Nautilus Scripts 191112 # Right-click file and run this script to create a new mime filetype # based on the extension. If no type is entered then it prompts to # remove the filetype if a previous type was defined using this script. # If a type is entered then prompts for the comment field and whether # or not to keep the parent file type. Press F5 to update the # file manager to pick up the new type. Changes are local, delete # ~/.local/share/mime to undo all changes. mimedir="$HOME/.local/share/mime" packagesdir="$mimedir/packages" filename="$1" extension="${filename##*.}" if [ "$extension" != "" ];then mkdir -p "$packagesdir" mimexmlfile="$packagesdir/customtype_$extension.xml" newtype=$(zenity --title "Add new filetype for *.$extension files" \ --entry --text "New filetype... (for example text/sometype)\n\(clear to prompt to remove type)") if [ "$newtype" = "" ];then if [ -e "$mimexmlfile" ];then if zenity --title "Add new filetype for *.$extension files" \ --width 350 --question --text "Remove existing filetype?";then rm "$mimexmlfile" update-mime-database "$mimedir" fi fi else # new type specified if [ -e "$mimexmlfile" ];then #remove existing xml first and update rm "$mimexmlfile" #to pick up the parent filetype update-mime-database "$mimedir" fi oldtype=$(mimetype "$1"|cut -d: -f2|tail -c+2) > "$mimexmlfile" echo "<?xml version=\"1.0\" encoding=\"UTF-8\"?>" >> "$mimexmlfile" echo "<mime-info xmlns=\"http://www.freedesktop.org/standards/shared-mime-info\">" >> "$mimexmlfile" echo " <mime-type type=\"$newtype\">" comment=$(zenity --title "Add new filetype for *.$extension files" \ --width 350 --entry --text "Enter description for comment field...") if [ "$comment" != "" ];then >> "$mimexmlfile" echo " <comment>$comment</comment>" >> "$mimexmlfile" echo " <comment xml:lang=\"en_GB\">$comment</comment>" fi if zenity --title "Add new filetype for *.$extension files" \ --width 350 --question --text "Keep parent type $oldtype?";then >> "$mimexmlfile" echo " <sub-class-of type=\"$oldtype\"/>" fi >> "$mimexmlfile" echo " <glob pattern=\"*.$extension\"/>" >> "$mimexmlfile" echo " </mime-type>" >> "$mimexmlfile" echo "</mime-info>" update-mime-database "$mimedir" fi fi
------- end AddToFileTypes -------------------
------- begin AddToApplications --------------
#!/bin/bash # # "AddToApplications" by WTN 5/20/2012 modified 11/17/2013 # # This script adds an app/command/script etc to the list of apps # shown when associating files under Gnome 3. All it does is make # a desktop file in ~/.local/share/applications, it doesn't actually # associate files to apps (use Gnome for that). Delete the added # customapp_name.desktop file to remove the app from association lists. # If run without a parm then it prompts for a command/binary to run. # If a parm is supplied then if executable uses that for the Exec line. # appdir=~/.local/share/applications prefix="customapp_" # new desktop files start with this if [ "$1" != "" ];then # if a command line parm specified.. execparm=$(which "$1") # see if it's a file in a path dir if [ "$execparm" == "" ];then # if not execparm=$(readlink -f "$1") # make sure the full path is specified fi if [ ! -x "$execparm" ];then # make sure it's an executable zenity --title "Add To Associations" --error --text \ "The specified file is not executable." exit fi if echo "$execparm" | grep -q " ";then # filename has spaces execparm=\""$execparm"\" # so add quotes fi else # no parm specified, prompt for the Exec command # no error checking, whatever is entered is added to the Exec line execparm=$(zenity --title "Add To Associations" --entry --text \ "Enter the command to add to the list of associations") fi if [ "$execparm" == "" ];then exit;fi nameparm=$(zenity --title "Add To Associations" --entry --text \ "Enter a name for this associated app") if [ "$nameparm" == "" ];then exit;fi if zenity --title "Add To Associations" --question --text \ "Run the app in a terminal?";then termparm="true" else termparm="false" fi # now create the desktop file - the format seems to be a moving target filename="$appdir/$prefix$nameparm.desktop" echo > "$filename" echo >> "$filename" "[Desktop Entry]" echo >> "$filename" "Type=Application" #echo >> "$filename" "NoDisplay=true" #doesn't work in newer systems echo >> "$filename" "NoDisplay=false" #for newer systems but shows in menus echo >> "$filename" "Name=$nameparm" echo >> "$filename" "Exec=$execparm %f" # I see %f %u %U and used to didn't need a parm, newer systems might be picky # according to the desktop file spec... # %f expands to a single filename - may open multiple instances for each file # %F expands to a list of filenames all passed to the app # %u expands to single filename that may be in URL format # %U expands to a list of filenames that may be in URL format # ...in practice all these do the same thing - %F is supposed to pass all # selected but still opens multiple instances. If %u/%U get passed in URL # format then it might break stuff.. so for now sticking with %f echo >> "$filename" "Terminal=$termparm" #chmod +x "$filename" #executable mark not required.. yet.. # when executable set Nautilus shows name as Name= entry rather than filename # app should now appear in the association list
------- end AddToApplications ----------------
These can be added to the file manager's scripts directory, or
run from the command line. These scripts require the Zenity
utility.
AddToFileTypes creates a new file type based on the extension of
the specified file. The file should exist so it can pick up the
existing file type (if any) for the parent type but this is not
enforced (I run it from Nautilus Scripts or equivalent so didn't
bother with checking to see if the file exists). The parent type
is handy for inheriting existing associations, for example for
.bas files the usual text editing tools will still be available in
addition to the basic-specific tools that are added. Apps can be
added or removed for the new type independent of the parent type,
but any apps added or removed from the parent type will be applied
to the new type as well. The script first prompts for the mime
name for new file type, this entry should have no spaces, and
although not necessary should also include the parent type or
otherwise describe the type of file, for example text/bas or
application/something. If the type field is left blank and the
type was previously created by this script, then it prompts to
remove the file type (do this if you mess something up). Next it
prompts for a description of the file type, this is what appears
in the type field when right-clicking a file and selecting
properties. Finally it prompts to keep the parent type, select yes
or no. Select no if no parent type is listed or the parent type is
unknown (the only time it should display no parent type at all is
if ran from a command line and the specified file doesn't exist).
Important - always check first to see if the file type already
exists, can do this by right-clicking the file and selecting
properties. Turned out I already had a file type defined for .bbc
files, was called "bbc document (application/x-extension-bbc).
AddToApplications adds a program to the list of applications the
file manager presents when associating files, if the program isn't
in a path directory (like /usr/local/bin) then the full path to
the program file or run script must be specified. If no parameter
is specified then it prompts for a command line, anything can be
entered but the script assumes the associated filename will be
added to the end of the command line. This script isn't strictly
necessary when using MATE's Caja file manager as it already
permits associating arbitrary commands, but it can still be handy
since it allows specifying a more readable name and whether or not
to run in a terminal window. Once it finds the file and makes sure
it's executable, or a command line has been entered, then it
prompts for a name for the application, this is what is displayed
by the file manager's open with entries when right-clicking.
Finally it prompts to run in a terminal, click yes or no, then
creates a desktop file in the ~/.local/share/applications
directory. Files added by this script start with "customapp_" and
can be simply deleted, however you might have to list from a
terminal using ls to see the actual filename.. some file managers
display the name field of .desktop files, some don't or only do if
marked executable. Presently, at least on my Ubuntu 20.04 system,
desktop files don't have to be executable to be used for
associations, uncomment the chmod line if they need to be.
8/20/20 - I need to make an auto-shutoff circuit for one of our
products, all it has to do is monitor the current flow and if it
stops changing for a period of time, shut off the power. Cycling
the main power switch restores operation. The circuit is simple, a
PIC10F222 6-pin processor, an opamp to convert the current drain
into a voltage the PIC can read, and a MOSFET to switch the power.
Here's a bit about how I program PIC chips, and what it took to
get my tools working on this Ubuntu 20.04 system.
For simple 12-bit or 14-bit PIC programming I usually use my Simple2 compiler,
which turns simple source
code into an assembly
file that can be assembled using gpasm from the gputils
package. It's not really a compiler, more like a fancy string
substitution program written
in QBasic-style FreeBasic that understands
if/then/else/endif blocks and has a simple loop/next construct
that can only count backwards (because that's how the underlying
machine code instruction works). In my original Simple the
keywords mapped mostly one-to-one to Parallax instructions, but
the assemblers for that instruction variant are long expired so I
rewrote it to emit the equivalent Microchip instruction sequences
for the gpasm assembler (part of the gputils package), but didn't
change the language hardly at all other than adding a new raw
command that simply outputs anything following it starting at
column 1 (the existing asm command starts at column 2). I mainly
use Simple because I'm used to it and lets me program in what is
essentially assembly but with human-readable instructions and
structure without having to invoke goto for every decision and
loop. Another reason I use Simple is because there aren't that
many combinations and the code output is predictable, so it's
reliable and fairly easy to test. I've used the same binary since
2012, I hesitate to even recompile it. More about Simple2 here.
Rather than installing gputils fresh I copied the binaries from by 12.04 system.. but turns out it's the same 1.4.0 version offered by the package manager (there is a newer version on the gputils web site). For development when possible I prefer putting my tools in /usr/local/bin myself rather than installing from the package system to avoid the possibility that an update will break my build system. Getting simple2 working was easy, copied it and gpasm and the other gputils binaries into /usr/local/bin and gpasm's gputils directory into /usr/local/share, works fine. However the 32-bit binary does require installing 32-bit versions of a few common libraries.
Usually I use Simple2 with a script that invokes the assembler
after compiling...
----- begin Compile_Simple2 ----------------
#!/bin/bash # Compile_Simple2 # associate with ".sim" files to compile/assemble by right-click if [ "$2" = "doit" ];then dn=`dirname $1` fn=`basename $1` bn=`echo $fn | cut -f 1 -d .` if [ -e $dn/$bn.asm ];then rm $dn/$bn.asm;fi if [ -e $dn/$bn.lst ];then rm $dn/$bn.lst;fi if [ -e $dn/$bn.hex ];then rm $dn/$bn.hex;fi echo "Compiling $fn with simple2 to $bn.asm ..." simple2 $1 $dn/$bn.asm if [ -e $dn/$bn.asm ];then echo "Assembling $bn.asm with gpasm -i to $bn.hex ..." gpasm -i -n $dn/$bn.asm -o $dn/$bn.hex fi if [ -e $dn/$bn.cod ];then rm $dn/$bn.cod;fi echo --- press a key --- read -n 1 nothing else if [ -f "$1" ];then if [ -f $1 ];then xterm -e $0 $1 doit;fi fi fi
----- end Compile_Simple2 ------------------
...so I can write code into a .sim source file then right-click and select Compile_Simple2. Setting that up was easy, right-clicked a .sim file and ran my AddToFileTypes scripts, defined text/sim keeping the parent plain text type, then using Caja added Compile_Simple2 to the associated apps. For Nautilus would have had to right-click the Compile_Simple2 script and run my AddToApplications script (once done the easy way using Caja it also appears in Nautilus associations, but Nautilus does not permit associating directly to a program). All that works fine, can write code, compile it, and produces a hex file if there are no syntax or symbol errors.
Now for the real fun! I've been using the pk2cmd utility to program PICs using a Pickit 2 programmer from the command line, I would really like to avoid having to run Windows software in a VM (wine doesn't support USB) or using the massive MPLab X IDE system every time I have to program a chip, which when developing code might be hundreds of times before the program works right. So copied the pk2cmd binary and the PK2DeviceFile.dat file from my old system, did chmod u+s on the binary like I had to on my old system.. complained it couldn't find libusb0.1 so something. Found that and put it where it was on my old system, now it ran but said it could find the usb_init symbol which is normal when not running as root but I was root. Messed around in Users and Groups but everything matched how it was on my old system, tinkering with other stuff had no effect so figured I better get out of there before I break something. There was some really scary stuff in the pk2cmd readme about udev groups and config files and such but before going there fired up Google.
And found this web page.. Using
a PICkit2 on Linux. Turns out the source
for pk2cmd and a newer device
file at the moment are still available from the Microchip
web site, just not linked from their index or search pages.
Compiling was easy, after extracting the pk2cmd folder from the
archive dropped to a command line in the pk2cmd folder within the
main pk2cmd folder and entered...
sudo apt-get install libusb-dev libusb-1.0-0-dev libudev-dev
make linux
...already had the libusb packages, compiled first try. To
install entered sudo cp pk2cmd /usr/local/dev then in the
directory the latest device file was in, entered sudo cp
PK2DeviceFile.dat /usr/local/dev and it works, at least when
running with sudo but that's always been the case. Didn't have to
bother with the chmod u+s thing. Yay! The only hiccups were the
PIC10F222 chip does not support auto-detect, so had to specify the
chip with the -P option. Although the chip will run at 2V, it must
be programmed at 5V so for in-circuit programming the circuit must
be able to withstand that voltage level. Helpfully the pk2cmd
program told me the chip didn't support the 3.2V voltage I was
programming it at or I would have had a time figuring out why some
locations had errors, the PICs I'm used to program fine at 3V. Not
a problem for the circuit I'm working on now but something to keep
in mind when using that chip for other projects.
I'm just getting started with the PIC10F222 chip. It's got 511
12-bit words of program memory (the top word is for oscillator
calibration), a whopping 23 bytes of user ram, runs at 4 or 8mhz,
has a 8-bit analog to digital converter with 2 channels plus an
internal reference (so can determine its supply voltage) and 4 I/O
pins, one of which is input only (MCLR has always been like that).
Not bad for a 50 cent processor in a tiny SOT-23-6 package. I've
never programmed 10F parts using Simple2 before but it shouldn't
be any problem, the instruction set looks to be the about the same
as any other 12-bit PIC. Like other 12-bit PICs it only has a
2-level stack, so gosub can call only one more gosub or the
program will get lost. It doesn't have I/O direction registers,
instead has a TRIS 6 instruction that loads the tristate register
from W so will have to use a couple asm instructions for that.
9/29/20 - A couple weeks ago my Ubuntu 12.04 system (finally) bit
the dust. Literally.. power supply fan clogged and quit turning
followed by a breaker-popping bang. Copied over everything I
thought I might ever need from the 12.04's hard disk by
temporarily connecting it. The GUI isn't so great copying hundreds
of thousands of files, gets slower and slower and ... should have
used cp. Had a fleeting thought of maybe turning it into a VM but
that's a bad idea since every time I would use it the backup
program would back up a 500 gig virtual disk. That already happens
when I run Windows but at least that's "just" a 50 gig file and I
only use it when running Altium for PCB design. No.. time to move
forward.
By the time of the crash the new system did just about everything
I needed, the big exception was printing. Not really the fault of
the OS - cheap ink jet printers just suck - but the 12.04 system
worked with my HP2652 printer. Printing worked on the new 20.04
system when it was installed on the other new machine with the AS
Rock motherboard, even wireless so could print from either the old
or new machine. After moving back to the Gigabyte machine I added
a FS-N600 wireless card which installed fine and could see the
wireless printer, but wouldn't work - couldn't get past the
password setup. Whatever, connected via USB. Found the printer,
installed it, but trying to do anything resulted in a connection
error. Ran it through my old USB hub thinking maybe that'd slow it
down, no luck. Well crud, I really really need to print!
Didn't like the HP2652 anyway (max page size was 8" by 10" rather
than the usual 8.5" by 11") so in a fit of desperation dragged my
old HP1510 out of the closet and hooked it up. Previously it had
become non-functional, first complained that the ink I bought from
Amazon was counterfeit (which it probably was) then after getting
more ink it refused to work - that's when I got the HP2652. This
time, went through the setup, detected it and set it up but it
still wouldn't work. Crud I really really really need to print!!!
Pulled out the ink cartridges and reinstalled, fiddled with the
paper feed tray, pretty sure I whacked it a couple times, pressed
a couple buttons at the same time and it printed a short test page
- at least it printed something. After that printing worked fine..
printed the PCB parts placement sheets I needed before it changed
its mind.
Scanning works but not crazy about the new included "Document
Scanner" application (previously Simple Scan) - it only saves PDF
which is almost always not what I want.. so to use have to scan,
save as PDF, open pdf, take a screen shot, fish out the dump file
and load it into an image editor to fix up. Previously could save
directly to JPG and edit only to set the desired resolution, color
depth etc. To get back the old functionality installed xsane, it's
more complicated but works well.
For image editing I'm still using IrfanView under wine. I
use version 4.25 from 2009 along with a script that converts the
file path/name separators from "/" to "\"...
------------ begin IrfanView ------------------------------ #!/bin/bash winpath="$1" if [ -n "$1" ];then echo "$1" | grep "/" &> /dev/null && winpath="Z:${winpath//\//\\}" fi wine "C:\Program Files (x86)\IrfanView\i_view32.exe" "$winpath"
------------ end IrfanView --------------------------------
...this might not be needed with newer versions but still need
some kind of script for launching and association. I use Irfanview
for cropping, changing the image size/resolution, converting to
grayscale, fixing gamma (auto-correct usually does the trick),
saving as different file types, simple copy/paste editing for
cleaning up hand-drawn diagrams and other simple editing tasks. I
have found nothing native to Linux that can do what IrfanView does
as simply as it does it.. with other software have to deal with
layers, drawing tools and it takes too long to do simple things.
With IrfanView the default mouse click/drag action is select
region so I can quickly crop and copy/paste and it shows the
selected region so I can plug those numbers into ImageMagick's
convert utility for cropping a bunch of images at the command
line.. handy for processing multiple screen dumps so that they all
come out the same size. But there was a bit of a hitch with the
new software...
Properly cropping GIF images with
convert
ImageMagick's convert utility does not reset the canvas size of
GIF images when using just -crop. For example...
convert -crop 500x300+20+40 orig.gif new.gif
...does not work right with some programs, but...
convert -crop 500x300+20+40 +repage orig.gif new.gif
...properly trims the image. This must be a fairly new thing,
under 12.04 I never had to do that (or the apps ignored it).
Previously on the new system was having to run each converted
image through IrfanView to fix, but much better to crop properly
to begin with. That's my command line discovery of the day!
Anyway...
Other than a couple minor things, both of my new ZaReason systems
work well.. back in the groove. One thing I wish I could figure
out is getting Caja to automatically thumbnail PDF files - I use
that visual clue when hunting down docs. All other Caja
thumbnailing works as far as I can tell, just PDF and that works
too if I open the folder in Nautilus to create the thumbnails..
just won't do it on its own. I need to double-check that with the
system at the shop, there I'm running MATE as my default session.
When I was setting up MATE on the shop system I didn't encounter
any major bugs with mate panel (like items disappearing when
trying to move) but it did give an error about removing
incompatible widgets when I first started it, after that it has
been fine but I don't push that system that much, it's mainly for
looking up schematics and other internet stuff. I found something
called "Caffeine" that prevents the screen from blanking, never
did find a MATE setting that fully prevented that. Still have to
remember to activate. On startup MATE on my shop system blinks the
desktop a few times before it settles down.. bit smoother on my
main system except when switching from Gnome to MATE without
restarting - that resulted in major blinking then crashed Caja
(for some reason the system thought the gnome-flashback session
was still running) but it recovered by itself. Might use the MATE
session for awhile now that it doesn't blank out.
9/30/20 ...and back to gnome-flashback.. this time because of app
menu behavior, in particular items I added myself had moved
categories. The root cause seems to be the XDG_MENU_PREFIX stuff -
I get the idea, only show apps relevant to a particular desktop
environment, but the implementation leaves users guessing what
happened to their apps. This isn't specific to MATE - Gnome Panel
aka flashback does it too. Overall probably a good thing to keep
users from running incompatible apps, but I don't think the
intention was for menu entries I entered myself to go missing,
stuff like that encourages me to stick to one environment. Since
I've used gnome panel v3 for more than half a decade I'm used to
it and in all the changes going from 12.04 to 20.04 it's the one
thing that hasn't changed much, I feel at home.
But I still absolutely need and love MATE - Caja saved by
computing sanity by giving me back a real desktop, the
alternatives simply don't work for me (I tried to like Gnome
Shell's desktop replacement but after a certain level of
complexity it just doesn't do what I need). Nautilus has been
reduced to the thing I run to make PDF thumbnails show.. after
having so many of the features I use removed that's almost all I
use it for. I also prefer the MATE versions of common apps - the
Pluma editor, mate-terminal etc - they still have a menu bar and
obey my theme requests. I didn't bother with flashback etc on the
shop computer, went straight to installing
mate-desktop-environment, after adding caffeine it works fine.
The next few years will be interesting (in life too but this is
regarding comp stuff). I don't know what direction Gnome is headed
anymore, each iteration seems to simplify to the point of
uselessness (IMO), great for users who just surf the web and do
simple tasks but not so great for someone like me who needs to
juggle a dozen things at once. I absolutely NEED shortcuts to my
work on my desktop and the ability to put them where I want, to be
able to make a temp file or folder when needed, a properly nested
app menu and a task bar to quickly jump between windows (not apps,
windows.. might have half a dozen instances of the same app open
at once). My work depends on it. I also need the abilities of the
underlying Linux OS (as in running native Linux apps, terminal,
compiling 'nix stuff, emulating almost any other computer/OS etc),
so even though Windows does provide a good desktop it doesn't work
for me except in a VM for running the very few Windows apps I use.
Mainly just Altium unless I'm testing something else, the other
Windows apps I use work under wine. Ubuntu 12.04 was the first
version of Ubuntu I used that had Gnome 3 - at the time many
disliked the shell but all the parts were there to put together a
functional desktop using only Gnome apps. This is no longer the
case. Anyone's guess as to whether gnome-panel will stick around,
frankly I was surprised it was still available but perhaps there
is still demand for a more traditional desktop environment.
10/2/20 - Fixed the PDF preview problem! (!!) Ran across a Debian
forum post, the issue seems to be evince, don't really need
it, MATE's Atril works well as do others, so removed evince and
.cache/thumbnails, made Atril the default PDF reader and rebooted.
Glad that's sorted.
10/17/20 - The simple "Software Updater" app has a couple
"issues" (bugs or features is a matter of opinion) - the main
issue is it is incapable of doing an update that involves
replacing dependencies when the new version requires uninstalling
something, in such cases it offers to do a partial upgrade
instead, and doesn't touch the upgraded app that now requires
something to be uninstalled. This is the safe thing to do but it
does happen quite frequently and once it starts the "error" won't
go away on its own and the affected software won't be updated. The
fix is trivially simple - install and use the Synaptic package
manager. After running reload package files (unless you just
canceled the partial upgrade, then it's already loaded), mark all
upgrades and it will tell you what it needs to remove to apply the
update. Usually (as in almost always) it's an old incompatible
library or something. Unless whatever it wants to remove is
actually needed, just confirm, apply, done. My opinion is the
Software Updater app should prompt to remove incompatible packages
itself, it's a common thing that confuses non-technical users.
The other "issue" is sometimes Software Updater doesn't update
everything, even after saying the system is up-to-date using
Synaptic shows more packages that can be updated, including fairly
important stuff like Gnome and window managers. Again possibly
playing it safe but confusing and making it so that without
Synaptic (or the equivalent apt commands) one doesn't know if
everything really is up-to-date. These aren't major issues and
it's been like that ever since I can remember, but I'm a more
technical user and this is one of the kinds of things that Desktop
Linux detractors point to to say it's not ready for the masses.
[...] Little things matter!
12/15/20 - well updating sucks worse than I thought.. for audio
production I have to use jamin version 0.97.14 (deb is from the
Ubuntu 14.04 archive but it works just fine in 20.04) because the
0.98.9 version in the 20.04 repository does not work (more about
that in the AudioStuff section). No
problem, uninstalled then installed from the deb file then marked
Lock Version in the synaptic package manager. This works fine with
the normal Software Updater app, nicely skips over it. But
inevitably (because Software Updater skips some updates even when
told to notify for all) updates build up in synaptic, noticeable
every time something is installed. But.. if I mark all upgrades it
also marks jamin, even though I told it to lock the version, and
it won't let me deselect it (can only deselect all, it's all or
nothing) and if I proceed it will update it to the broken one.
So.. every time now I have to unlock and uninstall jamin, let it
do the upgrades, exit synaptic and reinstall jamin from deb, go
back into synaptic and lock the jamin version so regular updates
won't overwrite it. Multiple fails here... 1) the version of jamin
in the repository is broken, 2) Software Updater doesn't update
everything (let alone update something that requires uninstalling
anything), 3) the synaptic app doesn't respect its own lock
version flag when marking upgrades, and 4) once marked it provides
no means to unmark an undesired upgrade.
Normally I would rebuild an app I wanted out of the version
system and install it to /usr/local instead, but jamin is old and
the original source no longer compiles. But there's nothing like
it, it's almost like my secret sauce when doing mixes. No idea why
the working version was replaced with a broken version, need to
track down the source code for 0.97.14 and 0.98.9 to try to sort
it out. But that still doesn't fix the other issues which as
likely or not have some other justification.. not a rabbit hole I
want to pursue other than document the behavior and work around
it.
1/5/21 - Found a fix for locking jamin to the old version... use
the dpkg utility. The following command did the trick...
echo "jamin hold" | sudo dpkg --set-selections
To verify the status of a package use the command: dpkg
--get-selections | grep packagename
Worked like a charm, now synaptic and update manager won't touch
it.
10/27/20 - I wondered why the speed selections of the Frequency Scaling panel applet had little effect, discovered (after reading the docs) that it only displays and controls the clock rate of a single core. I have 12, no wonder. Generally the default "On Demand" setting is fine but sometimes the die temp gets uncomfortably high (up to 190F) with a heavy CPU load, when that happens I'd like to slow it down. All the cores, not just one.. I can't think of any user case where I would only want to slow down a single core of a multi-core system. The Frequency applet is handy for monitoring - given the random nature of the task scheduling generally what's going on in one core reflects them all (if they're all on the same profile anyway) - but not so good for selecting the profile. I found something called "cpupower-gui" that works, but still a few more clicks than I'd like.. want something I can click then select what I want and it does it and goes away. So I made this...
---------------------- begin CPUgov -------------------------
#!/bin/bash # CPUgov - set all CPU's to specified governor - 201027 # requires Zenity and the cpufrequtils package, and CPU/kernel # support for frequency control. For governor descriptions see... # https://www.kernel.org/doc/Documentation/cpu-freq/governors.txt # The cpufreq-set binary must be made root suid, i.e.. # sudo chmod u+s /usr/bin/cpufreq-set # ..otherwise this script has to run as root. maxcpu=11 # max CPU number to change selection=$(zenity --title "CPU Governer" --hide-header \ --column "" --list \ "Performance (maximum clock rate)" \ "On Demand (quickly adjust for load)" \ "Conservative (slowly adjust for load)" \ "Power Save (minimum clock rate)" \ ) gov="" if [ "${selection:0:3}" = "Per" ];then gov=performance;fi if [ "${selection:0:3}" = "On " ];then gov=ondemand;fi if [ "${selection:0:3}" = "Con" ];then gov=conservative;fi if [ "${selection:0:3}" = "Pow" ];then gov=powersave;fi if [ "$gov" != "" ];then for cpu in $(seq 0 1 $maxcpu);do cpufreq-set -c $cpu -g $gov done fi
---------------------- end CPUgov ----------------------------
This script requires zenity (usually already installed in Ubuntu)
and the cpufreq-set utility from the cpufrequtils package. While
the GUI utilities don't need root, for some reason the cpufreq-set
utility has to be run as root. So I cheated and did sudo chmod u+s
/usr/bin/cpufreq-set - usually it's not a good idea setting any
old thing to run with root permissions just to avoid entering the
password but in this case the security implications are minimal
and a whole lot better than setting the script itself to run as
root - it's just a clock scaler, I really don't want to be
bothered with a password every time I "shift gears". See the
kernel docs link for more info about how the governors work.. the
user and schedutil governors looked to be of limited use so left
those out.
11/21/20 - I've been looking for a Linux video player that
supported timeline thumbnails, similar to how many web and Windows
players work. Found one called MPV
(it's in the 20.04 repository) It doesn't support thumbnails
out-of-the-box but supports scripting and thanks to an addon
called mpv_thumbnail_script
it does what I want...

Setting up the script requires manual actions but wasn't
difficult - after downloading the zip from the github archive
extract it to a work directory, run make (or grab the files from
the releases
page) then copy the resulting
mpv_thumbnail_script_client_osc.lua and
mpv_thumbnail_script_server.lua files to the ~/.config/mpv/scripts
directory (after creating it if it doesn't exist), create the file
~/.config/mpv/mpv.conf (if it doesn't exist) and add the line
"osc=no" (without the quotes), and create the directory/file
~/.config/mpv/lua-settings/mpv_thumbnail_script.conf containing
the line (as an example) "autogenerate_max_duration=10000"
(without the quotes), that line tells it to auto-generate
thumbnails for videos up to 10000 seconds long (about 2.77 hours).
The docs have more examples for the conf file. For faster
thumbnail generation make a couple extra copies of the
mpv_thumbnail_script_server.lua file and it automatically
multitasks (cool trick!). By default it saves thumbnails to /tmp
and seems to have a limit to how much it saves there, so if your
system doesn't periodically clean out /tmp then every now and then
delete the /tmp/mpv-thumbnails-cache directory.
[11/28/20] Another handy MPV script is SmartHistory from Eisa01/mpv-scripts.
To install download the zip of the archive and copy the
SmartHistory-1.6.lua file to the ~/.config/mpv/scripts directory.
Has a very simple but useful function - when a video is reloaded,
pressing control-R will resume playback to the last playback
location.
Here's a script I made for running a python program that I
recently became aware of...
------------ begin YTDL -----------------------------
#!/bin/bash # YTDL 201116 # requires zenity xterm youtube-dl if [ "$1" != "" ];then # if parm(s) specified spt="$1" if [ "$1" = "spawn" ];then # if called from self shift # remove flag from cl fi # edit these as needed dldir="$HOME/YTDLout" # where to download to fnopt="%(title)s-%(id)s.%(ext)s" # how to name files clopts="--no-mtime" # other options, empty for defaults mkdir -p "$dldir" # make sure download dir exists youtube-dl $clopts -o "$dldir/$fnopt" "$@" # run the download command if [ "$spt" = "spawn" ];then # if spawned terminal then sleep 7 # wait a few seconds so messages can be read fi else # no parm, get url with zenity then launch in xterm url=$(zenity --title "YTDL" --width 400 --entry --text \ "Paste the URL(s) to download...") if [ "$url" != "" ];then # if something was entered then xterm -e $0 spawn $url # recall script with flag and url(s) fi fi
------------ end YTDL -------------------------------
Sometimes videos need adjusting for better playback, ffmpeg (or
avconv) is good for that...
ffmpeg -i in.mp4 -s 682x480 out.mp4 # resize a video
ffmpeg -i in.mp4 -b 1000000 -s 682x480 out.mp4 # resize and also limit bitrate
...and numerous other things. One thing I run into is when the
audio is out-of-sync with the video, the ffmpeg command to fix
that is a bit convoluted so made a command line script to do it
(placed in a path directory)...
------------ begin offsetaudio ----------------------
#!/bin/bash # offsetaudio 201119 - shift the audio in a video if [ "$3" = "" ];then echo "Usage: offsetaudio inputfile outputfile offset" echo "For example: offsetaudio in.mp4 out.mp4 -0.1" echo "to shift the audio ahead by 0.1 seconds" exit fi if [ ! -f "$1" ];then echo "File $1 not found" exit fi ffmpeg -i "$1" -itsoffset "$3" -i "$1" \ -vcodec copy -acodec copy -map 0:0 -map 1:1 "$2"
------------ end offsetaudio ------------------------
I haven't gotten back into video editing yet on the new system
but installed Flowblade, OpenShot and Shotcut from the repository,
that should get be by for when the need arises. I used to use
OpenShot on the old 12.04 system where it struggled but got the
job done, it should work a lot better on this new system. Also
have HandBrake installed, a GUI front end for ffmpeg with many
useful conversion presets.
11/29/20 - Trying out my usual audio production software on the
new system.. installed Ardour5, Jamin, TimeMachine, Audacity and
various LADSPA plugins from the 20.04 repository. Also installed
lame in case needed for MP3 export. Note that when it gets to the
Jack setup when installing, real-time must be enabled (checked)
and have to reboot before Ardour can create a session. Other than
that bump I had no problems importing some tracks I had and coming
up with a rough mix. I like Ardour 5, a lot smoother and nicer
than the version 3 I was using (my old computer couldn't run later
versions) but close enough to 3 that I could jump right in and
make it work without looking at docs.
The Jamin mastering program was a bit of a problem, the 0.98.9
version in the 20.04 repository was very buggy - the displays were
very slow, numbers mixed up in the limiter section, linear/log
slider didn't work and the peak/rms displays always read "0.0".
Found the 0.97.14 version I was previously using in the Ubuntu
14.04 repository archives, downloaded the deb for it and installed
that instead.. that version works perfectly just like I remember.
Locked the version in Synaptic so it won't try to upgrade it to
the buggy version (still have to be careful when marking upgrades
using synaptic). The mastering program isn't strictly necessary,
all it's needed for is overall EQ, multi-band compression and
final limiting, most of which is optional or can be done directly
in Ardour. I like using Jamin because it's a lot easier to set up
and adjust than plugins (the multi-band compressor plugin I found
has a ton of options, for most of which I have not a clue), and
being a separate program I don't have to muck up the main "clean"
mix with stuff that basically just makes it sound louder.
TimeMachine is just a simple Jack-based recorder program. It has
no options or dialogs, just click it when ready to record and
click it again to stop. Output is a time-stamped W64 file to the
home directory which can be imported into Audacity to trim, do the
fade-in and fade-out and export to the desired format, for me
that's usually 320K MP3. Audacity uses LAME for MP3 encoding,
should install the library automatically. When encoded at 320K
bits/second I can't really tell the difference between the MP3 and
the W64 it came from, despite a 90% reduction in file size.
Ardour, Jamin and TimeMachine tie together using the Jack audio
system. Jack permits any program's audio output to connect to any
other program's audio input and/or the system L/R input. So Ardour
connects to Jamin which connects to TimeMachine and the system. If
Ardour is also connected to system then it'll create a funky
unwanted latency echo but it's easy to fix up, just right-click
the track, select output, unselect system and on the other tab
select jamin. Similarly with Jamin, select ports/outputs and add
TimeMachine.
Here's Ardour/Jamin/TimeMachine in operation during a mixdown...
(click for bigger)
So yay, audio-production ready. I've been thinking about getting
a multi-track recorder, something like the Tascam DP-24SD, but
this software setup should work with anything that outputs WAV
files, which is practically any project studio these days. Not
interested in using Ardour or other software to do the actual
recording, for that I prefer a machine or at least a dedicated
ProTools etc setup (the machine is much cheaper).
11/30/20 - I did manage to crash Jack, used the amplifier plugin
to overdrive a distortion plugin (can't remember which one..
wasn't the one in the screen shot above) and the audio just died,
all it would do is click when started and stopped - guess I blew
the simulated amp. Saving and exiting all Jack apps then
restarting fixed it so no big deal. I've run into buggy plugins
before, just have to learn which ones work and which ones to be
careful with.
One kinda huge issue with Jack is when it's running, anything
that isn't Jack-aware won't work. There's a package called
pulseaudio-module-jack that's supposed to let normal pulseaudio
apps work while Jack is running, various usages are documented on
this Ask
Ubuntu page but so far haven't gotten anything work. Some
people have gotten it to work but seems very hit and miss and
system-dependent. After going through about half a dozen audio
players with no luck (some like alsaplayer didn't work even when
Jack wasn't running..) finally found a player called "moc" that
actually works, auto-detects the sound system so plays the same
with Jack or Pulse/Alsa. It's a command-line terminal program so
to use from a file manager via association made a script that runs
xterm -e mocp "$1" so the player will show - after running have to
hit enter to start playing. Closing the window doesn't stop
playback so the next line in the script is mocp -x to stop the
playback process. Jack is very powerful and makes Linux audio
production practical, but it sure is a pain finding ordinary stuff
that works with it. Getting pulseaudio-module-jack working
seamlessly would be great, but for now just being able to play an
audio file while Ardour is running is the main use case.
12/8/20 - Sometimes one of the hardest parts of figuring out how
to do some computer-related task is knowing what tools are
available, and often already installed. Usually I start with
googling what I want to do then once the appropriate commands are
known then it's a fairly simple matter of doing man someprogram to
figure out how to use the stuff in a script. Was browsing about
the other day and ran into an easy way (that I didn't know about)
to call up an index of all installed man pages - the man -k
command aka apropos (who knows how they come up with these names).
The basic syntax is man -k [-s section#] "string". For example man
-k "zip" lists every man page containing the string "zip" in the
description, man -k -s 1 "" lists every man page in section 1,
etc. Most of the useful stuff is in section 1 (user programs) and
section 8 (system programs). The list of all man pages is fairly
big so wrote a script that launches xterm and pipes the commands
into less, along with a bit of formatting. Launches xterm in the
background so if launched from a terminal then it returns back to
the terminal for entering further man commands for possibilities.
If a string is specified then filters by that string, otherwise
lists everything in sections 1 and 8. Not everything listed
corresponds to an actual binary, for example the nvme-help entry
is for the nvme binary using the help parameter. Close enough...
---------------- begin mandir --------------------------
#!/bin/bash # mandir [string] # shows a list of all or some man pages in sections 1 and 8 # uses xterm, uses /dev/shm for temp file, edit to change tempfile="/dev/shm/mandir.tmp" if [ "$1" = "doit" ];then lines=`apropos -s 1 "$2"|wc -l` extxt="" if [ "$2" != "" ];then extxt="containing \"$2\"";fi echo "There are $lines man entries in section 1 $extxt">"$tempfile" echo "">>"$tempfile" apropos -s 1 "$2"|sed 's/ (1) / /'|\ sed 's/ //' |sed 's/ - / /' >>"$tempfile" echo "">>"$tempfile" lines=`apropos -s 8 "$2"|wc -l` echo "There are $lines man entries in section 8 $extxt">>"$tempfile" echo "">>"$tempfile" apropos -s 8 "$2"|sed 's/ (8) / /'|\ sed 's/ //' |sed 's/ - / /' >>"$tempfile" cat "$tempfile"|less else xterm -geometry 120x50 -e $0 doit "$1" & sleep 5 rm "$tempfile" fi
---------------- end mandir ----------------------------
The output looks something like...
There are 2557 man entries in section 1
atari800 emulator of Atari 8-bit computers and the 5200 console
fbc The FreeBASIC compiler
2to3-2.7 Python2 to Python3 converter
411toppm convert Sony Mavica .411 image to ppm
7z A file archiver with high compression ratio format
7za A file archiver with high compression ratio format
7zr A file archiver with high compression ratio format
as the portable GNU assembler.
atril The MATE Document Viewer
mate-disk-usage-analyzer A graphical tool to analyse disk usage
busybox The Swiss Army Knife of Embedded Linux
...etc. After relaunching itself in a parallel xterm it waits 5
seconds (long enough to process) then deletes the temp file and
returns to the terminal so that the xterm window containing the
man page list can be browsed and closed when needed.
12/12/20 - A neat trick when using the mandir script.. the less
file viewer can run shell commands by typing !command, so to pull
up the man page for any entry just type !man[space] then use the
mouse to highlight an entry, press the middle mouse button to
paste it after the man command, then press enter. After reading
the man page press Q then press enter and it goes back to the list
at the previous position.
12/15/20 - I'm often on the lookout for programming languages to
learn that can potentially make what I do easier, in particular
cross-platform languages where I can take (mostly) the same code
and compile it for Linux or Windows (bonus points if I can
cross-compile but if the Windows version of the compiler can run
under wine that's good enough). Most of the "apps" I make are
simple console things, for play and also for work, but
occasionally simple graphics is nice. For example the "plotlog"
program I use to monitor the progress of evolving core warriors,
visible in the first screenshot on this page. My work apps tend to
be simple and console-based but need to be able to do serial
communications over USB and have good screen control - my
simplistic UI's are bad enough so need to at least be able to put
text and accept input from anywhere on the screen. Usually
FreeBasic is my go to for these kinds of apps - programs compile
from a command line for Linux or (with wine) for Windows, any
OS-specific differences can be programmed so only one source file
is needed. Lately I've been playing with BBC
Basic, it isn't really a compiler but the run time is so
fast it feels like it's compiled and the Windows version can
"compile" all the code into a single compact exe. Both FreeBasic
and BBC Basic are similar enough to 8-bit MS BASIC and PC QBasic
that I can write most code quickly without much thought, and
simple enough so when I do need something fancy I can find it in
the docs. I don't program PC code very often but when I do it's
usually because I need to do something (sooner rather than later)
so having a language I am familiar with is a big productivity
help. C is too complicated (and bug prone) to do much of anything
quickly, not familiar enough with Python (and it's a moving
target), so usually end up using some kind of BASIC if what I need
to do is more than I want to do with bash.
Then there's Free Pascal...
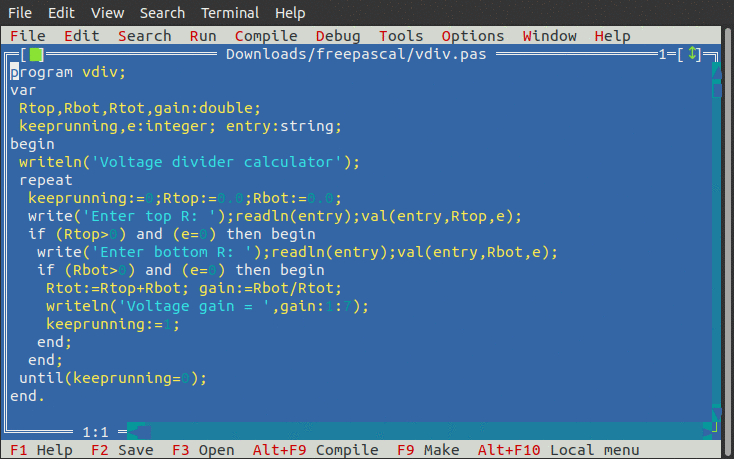
/usr/lib/x86_64-linux-gnu/fpc/$fpcversion/units/$fpctarget
/usr/lib/x86_64-linux-gnu/fpc/$fpcversion/units/$fpctarget/*
Didn't have much luck getting the help interface to work, instead
made a symlink to the HTML docs installed under
/usr/share/doc/fp-docs/.
The IDE has a few things that might be handy but for basic usage
it's just as easy (or easier) to use an editor and compile from
the command line. Using fpc progname.pas from the command line
(with no other options) makes smaller binaries than the IDE
settings, but it outputs a funny warning ending with "did you
forget -T?" (which has nothing to do with it). This is a known
message from ld and can be ignored, I used a patch utility called
"ldfpcfix" that
finds the message in the ld binary and plops a 0 on it to silence
it, crude but got rid of the message.
For screen control the most direct way to do it is to embed ANSI
codes.. i.e. write(#27'[37;44m'#27'[2J'#27'[H'); - that sets the
color to white on blue, clears the screen and homes the cursor.
Probably not that portable though. The Crt unit (use crt;)
provides more standard stuff like GotoXY, ClrScr, TextBackground,
TextColor and commands for checking for and reading keystrokes
(among things) that should work the same for Linux and Windows.
Free Pascal is vast! Has just about everything a (normal)
programmer might need and then some.. of course I tend to do odd
stuff like shell a 32-bit binary from the '90's millions of times
and expect no overhead or memory leaks, or more practically, make
control apps that communicate to embedded hardware over a USB
serial port. Free
Pascal shelling looks easy enough, many ways. Found another
way digging through the docs.. Popen
(for pipe open) - shells a program then can play it like a puppet
through stdout/stdin. Serial communications is fairly easy with
FreeBasic, essentially an open com function with port, baud rate
and options then read/write/close like any other file, other than
the port device name itself, the code is portable between Linux
and Windows. Free
Pascal serial communication looks a bit trickier. There is a
simple serial unit named simply "serial" but the only
documentation is what's on the wiki and the unit source code
itself. But it looks simple enough, might work fine.
Then it hit me as I was looking at the serial.pp and other unit
code... this thing can reach into the guts of the OS through
syscalls and do pretty much anything the user has permissions to
do. It's kind of like C but with a more digestible syntax, real
words instead of { } && or was it & and it doesn't
force me to use pointers (which it has if I need them but in
general I avoid numbers pointing to raw memory locations if I can
help it, my code tends to not blow up as much). The by-value or
by-reference parameter distinction makes much more sense,
by-reference does the same thing as pointers without having to
remember * (or else).
There are a LOT of units (got 970 here), a lot more than what's
in the docs.. to make a list enter something like this... (edit
for version)
find /usr/lib/x86_64-linux-gnu/fpc/3.0.4/units/x86_64-linux | grep ".ppu" > units.txt
If the source package is installed then each of these roughly
corresponds to .pp or .pas files under
/usr/share/fpcsrc/3.0.4/packages [subdir] /src or /src/unix
[name]. For example the unit file...
/usr/lib/x86_64-linux-gnu/fpc/3.0.4/units/x86_64-linux/rtl-console/crt.ppu
...corresponds to the source file...
/usr/share/fpcsrc/3.0.4/packages/rtl-console/src/unix/crt.pp
...or the crt.pp file in ../src/win/ for the Windows version.
Some don't have architecture folders, the files are just under
../src/. Need to make a program that indexes all this stuff into
an HTML index page that links to the source files.. Pascal
practice? Would be fairly easy with BASIC but trying to learn
something new.
12/16/20 - Came up with this thing... [updated]
// mkunitindex3.pas - 12/17/2020 (mod with procedure) // Make html index of installed units pointing to corresponding FP source. // For stock Ubuntu 20.04 fp 3.0.4 install, edit for other versions. // No error checking other than to see if the units list got generated, // any other error will halt with a run-time error. program mkunitindex3; uses sysutils; var fin:text; //input file handle (text is handle type for text files) var fout:text; //output file handle var tmpunits:string; //name of temp units list file var tmpscript:string; //name of temp script file var tmpout:string; //name of temp html file var tmpout2:string; //name of sorted temp html file var outfile:string; //name of HTML output file var r:integer; //used for return vals and a temp integer var inputstr:string; //lines read from units.txt and for section/name var section:string; //section path, including trailing / var sourcenam:string; //name of ppu file var sourcepas:string; //full path to corresponding source file var sourcepath:string; //base path to fpc source code var unitcount:integer; //count how many entries found var failcount:integer; //count how many entries not found var ppupath:string; //base dir for .ppu files var tempstr:string; // helper procedure - if parm exists as file, set sourcepas to parm // if sourcepas is already set then print warning instead procedure trymatch(s:string); begin if fileexists(s) then begin if sourcepas='' then sourcepas:=s else writeln('not rematching '+s); end; end; // main start begin outfile:='units_source_index.html'; //name of output index file // ------- install-specific setup ---------- ppupath:='/usr/lib/x86_64-linux-gnu/fpc/3.0.4/units/x86_64-linux/'; sourcepath:='/usr/share/fpcsrc/3.0.4/'; // ------- temp file names ----------------- tmpunits:='tmpunits_.tmp'; //name of temp file containing raw unit list tmpscript:='tmpscript_.tmp'; //name of temp script tmpout:='tmpout_.tmp'; //name of temp HTML out tmpout2:='tmpout2_.tmp'; //name of sorted temp HTML out // ----------------------------------------- unitcount:=0; failcount:=0; writeln('Generating '+outfile+' containing index of unit source...'); assign(fout,tmpscript); //assign the temp script name to fout handle rewrite(fout); //create and open file for writing writeln(fout,'find '+ppupath+'|grep ".ppu">'+tmpunits); //write find command close(fout); //close the output file ExecuteProcess('/bin/bash','./'+tmpscript,[]); //run bash to run command if not fileexists(tmpunits) then begin writeln('Failed to create units list'); exit; end; erase(fout); //erase the temp script file (by handle) assign(fin,tmpunits); //assign the units list file to the input handle assign(fout,tmpout); //assign the temp output file to the output handle reset(fin); //open input file for reading (funny name for open) rewrite(fout); //crate and open output file for writing while not eof(fin) do begin //loop until no more input lines readln(fin,inputstr); //read line from unit file delete(inputstr,1,length(ppupath)); //remove the unit base path r:=pos('/',inputstr); //get the position of the path separator if r>0 then begin section:=leftstr(inputstr,r); //part to left of / including / sourcenam:=rightstr(inputstr,length(inputstr)-r); //part to right of / r:=pos('.',sourcenam); sourcenam:=leftstr(sourcenam,r-1); // remove .ppu extension sourcepas:=''; // try to find the corresponding source tempstr:=sourcepath+'rtl/'; //rtl/linux and /rtl/unix subdirs trymatch(tempstr+'linux/'+sourcenam+'.pp'); trymatch(tempstr+'linux/'+sourcenam+'.pas'); trymatch(tempstr+'unix/'+sourcenam+'.pp'); trymatch(tempstr+'unix/'+sourcenam+'.pas'); tempstr:=sourcepath+'packages/'+section+'src/'; //packages/src subdirs trymatch(tempstr+sourcenam+'.pp'); trymatch(tempstr+sourcenam+'.pas'); trymatch(tempstr+'unix/'+sourcenam+'.pp'); //packages/src/unix subdirs trymatch(tempstr+'unix/'+sourcenam+'.pas'); trymatch(tempstr+'linux/'+sourcenam+'.pp'); //packages/src/linux subdirs trymatch(tempstr+'linux/'+sourcenam+'.pas'); if sourcepas='' then failcount:=failcount+1 //no match found else begin unitcount:=unitcount+1; tempstr:='---------------------------'; // spacer string r:=(length(tempstr)-1)-length(sourcenam); // calculated needed length tempstr:=sourcenam+' '+leftstr(tempstr,r); // prepend name to it writeln(fout,tempstr+'- <a href="file://'+sourcepas+'">'+sourcepas+'</a>'); end; end; // terminate the if path separator exists block end; // terminate the while not eof loop close(fin); //close input file erase(fin); //delete temp units list close(fout); //close temp output file // sort the html output... assign(fout,tmpscript); //assign the temp script name to fout handle rewrite(fout); //create and open file for writing writeln(fout,'sort<'+tmpout+'>'+tmpout2); //write sort command close(fout); //close the output file ExecuteProcess('/bin/bash','./'+tmpscript,[]); //run bash to run command if not fileexists(tmpout2) then begin writeln('Failed to create sorted index'); exit; end; erase(fout); //erase the temp script file assign(fout,tmpout); erase(fout); //erase unsorted temp output assign(fin,tmpout2); reset(fin); //open sorted temp output for read assign(fout,outfile);rewrite(fout); //create/open output HTML file writeln(fout,'<html><head></head><body>'); //start the HTML file writeln(fout,'<H3>Index of Free Pascal unit source code</H3><pre>'); while not eof(fin) do begin readln(fin,tempstr); writeln(fout,tempstr); //copy all lines end; writeln(fout,'<br></pre><p></body></html>'); //finish html file close(fin); close(fout); // close files erase(fin); // erase sorted temp output writeln('Done, made ',unitcount,' entries, ',failcount,' units not found'); end.
This program shells a command that generates a list of installed ppu unit files then parses it to generate an HTML index file that points to the corresponding unit source code, if it can find it. Out of the 970 ppu files I had installed, it found a pas or pp source file for 701 of them, the other 269 are for something else or don't apply to my system (I only looked for files for generic, linux and unix architectures). Obviously the FPC source code has to be installed for this to work, it's specific to version 3.0.4 installed from the repository on Ubuntu 20.04 but should be easy to adapt for other installs, edit the settings for ppupath and sourcepath. Note that some of the indexed source files under the /rtl/ directory aren't really all there is to it, particularly the all-important system unit - the system.pp file is more of a stub, according to the file comments "These things are set in the makefile, But you can override them here". However, all the source for the extra sysutils unit seems to be there.
A lot of new stuff (for me) to parse here. The basic core language is very simple, almost trivial. Which is very good, simple programs that just need to prompt for input, do some calculations and print the results don't have to be bogged down with the complexity needed for more sophisticated programs. Hello World is just...
program hello; begin writeln('Hello World'); end.
That program if compiled using the "fp" IDE comes out a hefty
344K but unless using debugging features of the IDE then it's
easier to just use a text editor and compile from the command
line. Compiling with the command line "fpc hello.pas" produces a
181K binary, better yet compiling using "fpc -XX hello.pas" trims
it down to 31K. The -XX option specifies smart link, which I
presumes throws out extra library code that isn't used. The
mkunitindex.pas program compiled with the -XX option makes a 107K
binary, roughly comparable to other modern compilers but I have
heard that Free Pascal can get fairly bloated when using fancier
features.
For most of the stuff I write programs for, I need to prompt for
and get input, print stuff (sometimes with screen control),
control the flow of the program, do math, manipulate strings, read
and write files, and perform OS functions such as shelling
commands and deleting temp files. The mkunitindex program does
most of that except for getting input because it's
non-interactive. What follows is a sort-of overview of the basic
language based on what I've learned in the last day or so.
For decisions there's if condition then begin lines of stuff end
else begin more lines of stuff end; - the begin end blocks are
needed only for multiple lines, the semicolon after the last end
(or command if no begin end block) marks the end if the if
construct. One gotcha is for multiple conditions, the final
condition must be boolean - if a<0 and b>0 then doesn't work
but if (a<0) and (b>0) then works. If can be as simple or
complex if needed - if a=1 then b=0; if a=1 then b=0 else a=1; if
a=1 then begin thing1; thing2; end else thing3; - end only matches
begin, nothing to do with if itself. Thankfully there's no
'elseif' which is a confusing way to hide additional levels..
specify it directly.
For loops there's for var:=start to finish do stuff; while
condition do stuff; (those need begin end blocks if multiple
stuffs) and repeat stuff; stuff; stuff; until condition; (repeat
until doesn't require begin end block for multiple stuffs). There
is also break; to exit the current loop and exit; to exit the
current procedure. I think (can't find much about the simple stuff
in the docs) but that's what it does.
For subroutines there are functions that return a value and
procedures that don't return a value, otherwise they are about the
same. Both can change global values, or change variables passed to
it if set up that way in the declaration. Adding the trymatch
procedure to the mkunitindex program saved a few lines, made the
code "cleaner" and allowed me to add a check to warn if there was
already a match (there weren't any dups but know I know).
Stock string handling is pretty basic but the sysutils unit adds
a lot more stuff. Without sysutils you can combine strings using
+, p:=pos(substring,string) returns the start of substring in
string, string2:=copy(string1,start,length) copies part of a
string into another string, l:=length(string) returns the string
length, and my favorites - delete(string,start,count) deletes
count chars from a string starting at start, and
insert(substring,string,position) inserts substring into string at
a specified position. For string comparisons if s1=s2 and if
s1<>s2 work but < and > won't work for sorting [but
does work for type char]. Including the sysutils unit gets a few
more things like string=leftstr(string,count) and
string=rightstr(string,count), and a comparestr(a,b) function. No
BASIC-style MID$ equivalent but copy and the other functions can
do similar things. The val operation for converting a string to a
numeric variable is a bit odd, instead of a function it's a
procedure - val(string,var,e) computes the numeric value of the
string, puts it in var, and sets integer e to 0 if successful or
the problem character if not.
The stock string type is limited to 255 characters max unless
otherwise declared as string[n] where n is 1 to 255. These strings
are statically allocated thus very fast and cannot overflow,
anything added past the end is simply ignored thus they are safe
with unknown input. For dynamic strings use var:ansistring;
instead, these can grow to any size so have to be more careful...
avoid running something like var ha:ansistring;begin ha:='
';repeat ha:=ha+ha;until 0;end. The two string types seem to mix
ok, at least for simple stuff. Plain strings keep the string size
in the first byte whereas ansistring strings are null-terminated,
so internally they are very different.
Stock file handling is also pretty basic and the names are
somewhat unintuitive. File handling is done using handles, for
text files declare the handle as var f:text; where f is the handle
name. Assign(f,string) assigns a filename to a handle, the file
doesn't have to exist (yet) in the case of writes. Separate types
for files is needed so readln(handle,var) and writeln(handle,var)
can distinguish file I/O from console I/O. Reset(handle) opens a
file for reading, rewrite(handle) opens a file for writing,
append(handle) opens a file for append, close(handle) closes a
file, erase(handle) erases a file. Once a file is open then
readln(handle,string) reads a line from a file into string, and
writeln(handle,string) writes a string to the file. The
eof(handle) function returns true if there are no more lines left
in the file. These functions are fragile, unless other steps are
taken to trap errors if a file doesn't exist etc the program halts
with a run time error. Adding the sysutils function adds nicer
file handling functions like fileexists(string) that returns true
if the filename in string exists. The mkunitindex.pas program uses
fileexists to figure out if a unit file corresponds to an actual
source file.
For shelling helper scripts, the mkunitindex program uses the
simple but limited ExecuteProcess function. This is the most basic
of shells, requires the full path to program (it doesn't search
the path) passing only command line arguments and optionally
picking up the exit code. So for scripts I run "/bin/bash" which
is almost always valid with the name of a previously-written
script or command line to run for the argument. I probably could
put the command line in the bash argument but redirection can
complicate things and if something goes wrong I want it to leave
the script behind to see what went wrong.
That's pretty much the basics.. so much more to learn but I think
I've achieved "critical mass" with this Free Pascal thing, I like
it!
12/19/20 - Figured out a bit about FP's error handling, basically
have to include "uses sysutils;" and use the -Sx option when
compiling, this enables Try Except and Try Finally blocks, and
also enables better descriptions when run-time errors occur.
Here's a short program illustrating Try Except...
program errtest; uses sysutils; var a,b,c:real; begin a:=3.0;b:=0.0; writeln('Checking errors'); Try c:=a/b; writeln(c); Except writeln('Error!'); end; writeln('End of error checking'); writeln('Trying an unhandled exception..'); c:=a/b; end.
Compile with fpc -XX -Sx errtest.pas, running the resulting
errpass binary produces the following output (on my system)...
Checking errors
Error!
End of error checking
Trying an unhandled exception..
An unhandled exception occurred at $000000000040125F:
EDivByZero: Division by zero
$000000000040125F
A Try Finally block doesn't have a branch for error, instead
anything in the Finally section is always executed. This seems
redundant but the reason is if there is an exit command in the Try
block everything in the block is executed before exiting, Finally
provides a way to close files etc before exiting should an error
occur. Try Except and Try Finally cannot be mixed in a single
block but can nest them.. Try Try someerror; Except errorhandling;
exit; end; Finally alwaysruns; end; provides error handling and
makes sure cleanup happens before the exit. Nice!
Using a text editor and compiling with fpc works much better for
me than the fp IDE, the compiler specifies which line and column
has the error and what the error is. But it was inconvenient to
drop to a terminal to compile and test, not to mention clogging up
my command history, so I made a couple shell scripts. This script
compiles a Pascal source file in an xterm window, waits for a
keypress then removes the intermediate object file...
------- begin compile_fpc ------------------
#!/bin/bash # compile pascal program with fpc -XX -Sx and remove intermediate .o file # associate to pascal files if [ "$1" = "doit" ];then fpc -XX -Sx "$2" echo "----- press any key -----" read -n1 nothing else if [ -f "$1" ]; then xterm -e "$0" doit "$1" # remove object file pasfile="$1" noxfile="${pasfile%.*}" # strip extension rm "$noxfile.o" # remove .o file fi fi
------- end compile_fpc --------------------
...add it to the associations for Pascal files, which should
already be a defined file type otherwise best to create a new type
to keep Pascal-specific tools from appearing in the right-click
option for all text files. The Caja file manager permits
associating raw commands, for Nautilus have to make an application
desktop file for it to be recognized as an option, previously discussed. Also should work
as a file manager script.
Normally when running binaries no terminal is launched, so this
script launches a binary in xterm then waits for a keypress before
closing the terminal window... [updated 12/29/20 - fixed parm bug]
------- begin run_xterm -------------------
#!/bin/bash # run a binary in xterm, wait for key to exit if [[ "$1" = "__do_it__" ]] && [[ -t 1 ]];then PATH=.:$PATH # so ./ not necessary to run shift "$@" echo "----- press any key -----" read -n1 nothing else if [ -f "$1" ];then if [ -x "$1" ];then xterm -geometry 80x25 -bg black -fg green -fn 10x20 -e "$0" __do_it__ "$@" fi fi fi
------- end run_xterm ---------------------
...for this one I added a link to it to the scripts folder,
useful for many things and the system won't let me add right-click
apps for binary executable files. Also in a path directory
(.local/bin) so I can use it from the command line, including
passing any parms. Making it work as a file manager script was
slightly tricky as the file manager passes just the plain binary
name and the shell expects "./" in that situation, so added . to
the PATH variable. Changed my usual "doit" flag to "__do_it__" in
case the binary is named "doit", then it still checks to make sure
it's running in a terminal so even a file named __do_it__ won't
break it (just won't launch xterm if run from a terminal.. the joy
of code).
12/27/20 - Finally replaced my ancient cruddy javascript isbas.htm electronics calculator
with this Free Pascal program...
ECALCS now has its own page
in the electronics section
with docs and binaries. Updates to the program will be made there,
will try to leave the source linked below alone unless I find a
gruesome bug or something.
Here's the (Kate colorized) source code
for the ecalcs program, to compile it copy/paste it to a
file, say "ecalcs.pas", then compile the source using the command
line: fpc -XX -Sx ecalcs.pas (produces a 144Kbyte binary on my
system). It will also compile for Windows as-is using the command
line [wine] fpc.exe -Sx ecalcs.pas. It's a console program, has to
be run from within a terminal. To make a launcher for it that runs
it in an xterm window I used Caja/MATE's Create Launcher function
with the following command line...
xterm -geometry 80x25 -bg black -fg green -fn 10x20 -e ecalcs
...that assumes ecalcs is in a path directory such as .local/bin
otherwise have to specify the full path to the ecalcs binary. Or
can specify Application in terminal with just the ecalcs
path/binary to run it in the default system terminal. Stuff like
this is desktop environment dependent. Eventually I'd like to
learn how to use Free Pascal to make GUI programs but I'm not
there yet, and not particularly in a hurry since simple console
programs like this work fine for most of my programming and custom
calculation needs.
The ECALCS interface is like most of the stuff I make - old-style
and DOS-like. I used the crt unit to get the readkey function
which waits for a keypress then returns a single character which
is then used to run the selected calculation, this is faster than
having to press enter after the selection. To make things less
cluttered it doesn't redisplay the main menu every time, press
enter to redisplay the menu. Press Esc to exit the program. The
program doesn't cover simple calculations like ohms law, series
resistors and parallel capacitors, those are easily done using a
calculator app with minimal effort. Rather it focuses on
calculations I frequently have to do that require a more tedious
calculations, or in the case of the noise and capacitor charge
calculations, remembering obscure formulas. I found the capacitor
charge formulas in this RC
calculator on Bill Bowden's web site some time ago ago
(2008), those pages are now at Bowden's Hobby
Circuits.
I was using ANSI codes for screen handling.. positioning the
cursor, clearing, etc.. but to be compatible with ANSI-free
systems I replaced these with crt unit code like
GotoXY(1,WhereY-1); ClrEol; so it will work the same whether
running under Windows or Linux. The Windows version of Free Pascal
(3.2.0) installed just fine using wine, and registered itself to
the path so can be run using the command wine fpc.exe [options].
The -XX smart link option doesn't seem to do anything, perhaps
that's now the default (the exe size smaller than the Linux
binary). Also, -WC for console program isn't needed, with just -Sx
the resulting exe runs fine using wineconsole. Cross-platform
works.
A Text-to-Unicode Doodle Diagram
Converter
12/30/20 - This is kind of neat, it takes an ASCII doodle
schematic like...
.------------------------.
-- -- -- -- -' `- -- -- -- --
Antenna ---------------------*--- 51 ohm ---*--------------------- TV
-- -- -- -- -. | | .- -- -- -- --
| `--- 51 ohm ---* |
-- -- -- -- -' | |
Cable ---------------------*-- 100 ohm ---* |
-- -- -- -- -. | | |
| `-- 150 ohm ---' |
`------------------------'
...and turns it into a UTF-8 line drawing like...
┌────────────────────────┐
── ── ── ── ─┘ └─ ── ── ── ──
Antenna ─────────────────────┬─── 51 ohm ───┬───────────────────── TV
── ── ── ── ─┐ │ │ ┌─ ── ── ── ──
│ └─── 51 ohm ───┤ │
── ── ── ── ─┘ │ │
Cable ─────────────────────┬── 100 ohm ───┤ │
── ── ── ── ─┐ │ │ │
│ └── 150 ohm ───┘ │
└────────────────────────┘
In case the browser mangles that, here's how it looks in Xterm
with big green on black fonts...
The program supports several of the common symbol combinations I use when making ASCII schematics...
single-line conversions: -- -|- | .- -. '- `- -.- -'- -[ ]- (isolated dashes are not converted)
multi-line * conversions:
| | | | Top char can be | or .
*- -* -*- -*- -*- Left char can be - ' ` or . Right char can be - ' or .
| | | | Bottom char can be | ' or `
It takes more care with the * conversions to try to avoid
wrecking math formulas. Isolated dashes are not converted, they
have to have some kind of drawing symbol to the left or right. |
is always converted but looks about the same and are easy enough
to edit back if it matters.
Here's another conversion example of something a bit more
complicated, displayed using Gedit...
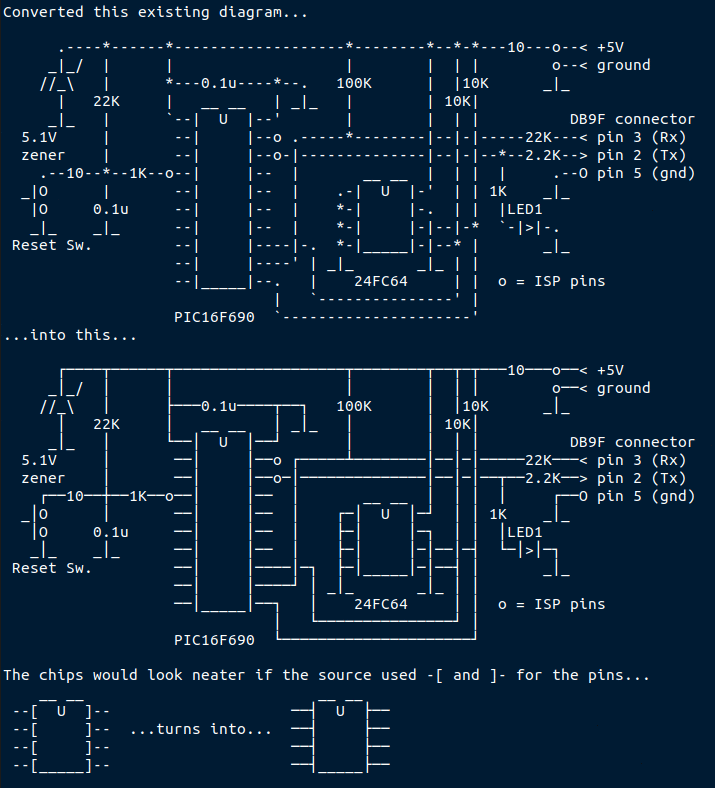
The program takes parameters for the input and output files, if
the output file isn't specified then outputs to stdout( the
terminal or a redirected file), and if neither file is specified
then inputs and outputs from stdin and stdout. If using
interactively from a terminal then press CTRL-D after the last
line to terminate the input and display the results. To get the
Unicode hex byte sequences I used my hex2utf8 Blassic script, used
the rounded versions of the corners, hopefully these display
correctly on most systems. [updated 5/15/21 - original was limited
to 256 lines, now handles up to 32767 lines and if exceeded
silently ignores the extra lines rather than throwing a runtime
error. Now tries to avoid converting unrelated ... sequences.
Corrected comments.]
Here's the Free Pascal source code...
// ascii2utf8 - 210515 WTN // This program replaces certain characters in an ascii schematic with // UTF-8 line drawing characters. Converts the following combinations... // -. -.- .- - -' -'- '- `- | -[ ]- (isolated dashes not converted) // | | | | in these the left - can be . or ' or `, right - // -* *- -*- -*- -*- can be . or ', top | can be . and the bottom | // | | | | can be ' or ` for tighter junctions // Avoids inadvertently converting repeating . as in this text follows... // The program requires 2 parameters for the input file and the output file. // Defaults to stdin and stdout if no parameters supplied, press control-D // to terminate input and display the results uses sysutils; type SA = array[0..32766] of string; type ASA = array[0..32766] of ansistring; var inputarray:SA; var outputarray:ASA; var infile,outfile:text; var x,y,lc,sc,outmode,maxlines:integer; var inputline,newstr,arraychr,leftchr,rightchr,topchr,bottomchr:string; begin maxlines:=32766; // size of input/output arrays outmode:=0; // 0=output to file 1=output to stdout (suppress messages) if paramcount>0 then begin if paramstr(1)='--help' then begin writeln('Usage: ascii2utf8 [infile [outfile]]'); writeln('Converts ascii line drawing chars to UTF-8 chars.'); writeln('If infile or outfile not specified then assumes redirection'); writeln('and suppresses messages. For interactive use press CTRL-D on'); writeln('on an empty line to terminate input and display the results.'); exit; end; if (fileexists(paramstr(1))=false) then begin writeln('input file not found'); exit; end; end; if paramcount>0 then assign(infile,paramstr(1)) else infile:=input; if paramcount>1 then assign(outfile,paramstr(2)) else begin outfile:=output; outmode:=1; end; reset(infile); rewrite(outfile); lc:=0; sc:=0; if outmode=0 then write('Reading input file... '); while not eof(infile) do begin readln(infile,inputline); if lc<=maxlines then begin inputarray[lc]:=inputline; lc:=lc+1; end; end; if outmode=0 then writeln('(',lc,' lines read)'); if outmode=0 then write('Processing... '); for y:=0 to lc-1 do begin outputarray[y]:=''; // start new empty output line for x:=1 to length(inputarray[y]) do begin arraychr:=copy(inputarray[y],x,1); newstr:=arraychr; leftchr:=' '; rightchr:=' '; topchr:=' '; bottomchr:=' '; if x>1 then leftchr:=copy(inputarray[y],x-1,1); if x<length(inputarray[y]) then rightchr:=copy(inputarray[y],x+1,1); if y>0 then topchr:=copy(inputarray[y-1],x,1); if y<lc-1 then bottomchr:=copy(inputarray[y+1],x,1); // change surrounding chars for more junction combinations if (topchr='.') or (topchr='*') then topchr:='|'; if (bottomchr='''') or (bottomchr='`') or (bottomchr='*') then bottomchr:='|'; if not ((arraychr='.') and ((leftchr='.') or (rightchr='.'))) then begin if (leftchr='.') or (leftchr='''') or (leftchr='`') or (leftchr='*') then leftchr:='-'; if (rightchr='.') or (rightchr='''') or (rightchr='*') then rightchr:='-'; end; // check for substitutions case arraychr of '-': if (leftchr='-') or (rightchr='-') or (leftchr='|') or (rightchr='|') then // ignore isolated - newstr:=chr($E2)+chr($94)+chr($80); '|': newstr:=chr($E2)+chr($94)+chr($82); // always convert | '''':begin if leftchr='-' then newstr:=chr($E2)+chr($94)+chr($98); // -' if rightchr='-' then newstr:=chr($E2)+chr($94)+chr($94); // '- if (leftchr='-') and (rightchr='-') then // -'- newstr:=chr($E2)+chr($94)+chr($B4); end; '`': if rightchr='-' then newstr:=chr($E2)+chr($94)+chr($94); // `- '*': begin if (leftchr='-') and (rightchr<>'-') and // | (topchr ='|') and (bottomchr='|') then // -* newstr:=chr($E2)+chr($94)+chr($A4); // | if (leftchr<>'-') and (rightchr='-') and // | (topchr ='|') and (bottomchr='|') then // *- newstr:=chr($E2)+chr($94)+chr($9C); // | if (leftchr='-') and (rightchr='-') and // | (topchr ='|') and (bottomchr<>'|') then // -*- newstr:=chr($E2)+chr($94)+chr($B4); // if (leftchr='-') and (rightchr='-') and // (topchr<>'|') and (bottomchr='|') then // -*- newstr:=chr($E2)+chr($94)+chr($AC); // | if (leftchr='-') and (rightchr='-') and // | (topchr ='|') and (bottomchr='|') then // -*- newstr:=chr($E2)+chr($94)+chr($BC); // | end; ']': if rightchr='-' then newstr:=chr($E2)+chr($94)+chr($9C); // ]- '[': if leftchr='-' then newstr:=chr($E2)+chr($94)+chr($A4); // -[ '.': begin if leftchr='-' then newstr:=chr($E2)+chr($94)+chr($90); // -. if rightchr='-' then newstr:=chr($E2)+chr($94)+chr($8C); // .- if (leftchr='-') and (rightchr='-') then // -.- newstr:=chr($E2)+chr($94)+chr($AC); end; // '\': newstr:=chr($E2)+chr($95)+chr($B2); // convert / and \ // '/': newstr:=chr($E2)+chr($95)+chr($B1); // (disabled) end; if length(newstr)>1 then sc:=sc+1; // count substitutions outputarray[y]:=outputarray[y]+newstr; // add orig/conv char to line end; end; if outmode=0 then writeln('(',sc,' substitutions made)'); if outmode=0 then write('Writing output file... '); for y:=0 to lc-1 do writeln(outfile,outputarray[y]); close(infile); close(outfile); if outmode=0 then writeln('done.'); end.
Originally the program also converted / and \ and used rounded
corners - looked great in the terminal and on the web on my Ubuntu
20.04 system, but some editors couldn't display the Unicode text
properly (such as Gedit) and it was a garbled mess under Windows
7, even after updating the browsers. Disabled the slash conversion
code and went back to the more compatible sharp corners (which
look fine), now it displays correctly in Gedit and on the web in
Windows. The problem wasn't that the symbols weren't supported,
they displayed fine but they were a different size - for line
drawing a symbol is useless if it has a size that's anything other
than exactly the existing fixed font size. Things might be
improved in later versions of Windows but don't count on proper
display of raw Unicode drawings on the web (and forget Android),
much better to take a screen dump of the figure displayed in a
terminal or editor and crop and use that.
New Pascal stuff learned... program at the beginning is ignored
by the compiler. To make an array first need to first do (for
example) TYPE SA = array[0..255] of string; then use VAR
arrayname:SA; .. a bit convolted but just how it's done. Use
arrayname[x] for elements. The command line can be accessed using
the paramcount and paramstr(n) functions, as with most languages
paramstr(0) is the program path/name. For file I/O, for standard
input or output is just assign input or output to the file handle
(I think that's cross-platform but lots better than /dev/stdin
etc). Control-D terminates an input stream when using stdin
interatively, triggers EOF (at first coded [*END*] etc but duh).
When redirecting output to a file, all normal message output
should be suppressed, not sure why but when I left the messages in
it made a mess of the output file. The program uses type string
for the input array so it won't blow up if used on a huge binary
or something, the output array is type ansistring to allow room
for expansion from the Unicode sequences.
Recently I upgraded my 20.04 stock wine 5.0 install to the new version 6.0 using instructions from OMG Ubuntu. Essentially...
sudo dpkg --add-architecture i386
wget -nc https://dl.winehq.org/wine-builds/winehq.key
sudo apt-key add winehq.key
sudo add-apt-repository 'deb https://dl.winehq.org/wine-builds/ubuntu/ focal main'
sudo apt install --install-recommends winehq-stable
Had already done the i386 part long ago. This removes the
existing wine install. Only do this if comfortable with
system-level changes and you have backups - expect breakage.
Possibly not compatible with the old winetricks package (which
complains), found something called q4wine that does some of what
winetricks used to do but also provides convenient access to wine
components for settings (winecfg), uninstalling apps and other
stuff.
The upgrade wasn't exactly transparent.. at first thought it was
broken, none of my desktop icons and menu entries for wine apps
worked. Right-clicking and running Windows apps in wine (using
scripts I had previously wrote) worked, had to go through a few
steps to download and install additional components but after that
all my right-click wine apps were fine. Turning to the broken
desktop files, found that they ran the command wine-stable, which
isn't provided by the wine-stable package (go figure..), changing
"wine-stable" to "wine" in the desktop file fixed it. Not wanting
to edit all my existing desktop files and menu entries, I tried to
create a symlink to the wine binary named
/usr/local/bin/wine-stable but that did not work - I guess it
really wants to be called wine. So instead made a script...
---------- begin /usr/local/bin/wine-stable -------------
#!/bin/sh wine "$@" &
---------- end /usr/local/bin/wine-stable ---------------
...that seems to work.. all of my existing 32-bit and 64-bit app
shortcuts launch now. This is probably only an issue with
shortcuts for apps installed using the old version, pretty sure
the desktop files created for newly installed apps won't try to
reference a non-existing binary.
The new version of wine is a major update from
the version 5 series. For the apps I use (Irfanview, LTspice and a
few others) it is noticeably faster and smoother and fixes a few
GUI bugs - most notably how in LTspice sometimes the button
tooltips would get caught in a flickering pattern, that no longer
happens. The Windows versions of the Free Basic and Free Pascal
compilers work ok but had a cosmetic issue.. running them (or any
app from a terminal using the wine command) produced a shower of
fixme:font messages. To get rid of those messages added the
following lines...
# fix wine 6.0 font fixme messages
export WINEDEBUG=fixme-font
...to the end of my .profile file in my home directory, takes
effect after rebooting. Change fixme-font to fixme-all to
eliminate all fixme messages (usually they are not important) but
the only fixme messages I'm seeing are about fonts unless running
GUI apps from a command line, and when doing that I'm used to
seeing all those messages.
One old program I very occasionally use - IDA Step Viewer - says
"Failed to create the Java Virtual Machine".. in a console it says
"Could not reserve enough space for object heap". It used to work
fine under wine. Don't really need that program but got a feeling
that's going to be an issue with other Java apps. Some exe files
(not installed apps) don't run if using right-click Open with Wine
but work using Open with Wine Windows Program Loader, which also
automatically runs wineconsole for console apps, so made that the
default action for exe files.
Although it's taking a bit of hacking to integrate, the upgrade
was well worth the effort - the stuff I use every day works better
than ever now.
Gnome Flashback Mutter session
2/7/21 - I like the Compiz window manager but lately it has been
causing issues with a few apps, most notably Firefox (especially
the latest version 85) which would flash obnoxiously when
selecting the window and sometimes showing an empty dialog window
(as in a frame with the app behind it showing through). The MPV
media player would also sometimes flash a bit when selecting the
window but held it together, that didn't bother me much but once
Firefox started acting up I had to do something. After a bit of
experimenting determined that the problem was being triggered by
Compiz, (not saying that's the root cause but) running the command
"mutter --replace" to run the Mutter window manager solved the
problem. Even better, resizing a MPV window now automatically
preserves the aspect ratio, wasn't expecting that but it's handy.
I had tried to enable a mutter flashback session before but the
old method of adding a new session - basically just duplicating
existing session files in /usr/share/xsessions and
/usr/share/gnome-session/sessions (and now scripts in
/usr/lib/gnome-flashback) - didn't work, even if only duplicating
the files with no changes other than the name in the xsessions
desktop file. Something has changed since Ubuntu 12.04, some
manifest somewhere or something. Finding docs is next to
impossible as almost always the info is out of date. But I
discovered a trick that makes all the extra editing unnecessary -
simply copy an existing .desktop file in /usr/share/xsessions - in
my case gnome-flashback-metacity.desktop - to a new name -
gnome-flashback-mutter.desktop - and edit it to change only the
Name tag, leaving everything else the same. Selecting that session
then boots to a metacity session with one difference -
$DESKTOP_SESSION and other environment variables now say
"gnome-flashback-mutter". Awesome, now all I have to do is
add a section to my "mystartapps.sh" script that runs on startup,
which now looks like...
-------- begin mystartapps.sh --------------
#!/bin/bash #if [ "$DESKTOP_SESSION" = "ubuntu" ];then # caja -n --force-desktop & # gnome-panel --replace & #fi if [ "$DESKTOP_SESSION" = "gnome-flashback-metacity" ];then caja -n --force-desktop & fi if [ "$DESKTOP_SESSION" = "gnome-flashback-compiz" ];then caja -n --force-desktop & fi if [ "$DESKTOP_SESSION" = "gnome-flashback-mutter" ];then mutter --replace & sleep 2 caja -n --force-desktop & fi if [ "$DESKTOP_SESSION" = "mate" ];then caffeine-indicator & fi
-------- end mystartapps.sh ----------------
I put a 2 second sleep between starting the mutter window manager
and starting Caja so the latter wouldn't launch in the middle of a
WM replace, which can be a bit jarring to apps. Originally tried
just using mutter --replace and compiz --replace as Gnome Panel
launchers but it didn't like that one bit. This method seems to
work fine. Also if you haven't read my previous Flashback mod
notes, Flashback's desktop must be disabled using dconf editor -
go to /org/gnome/gnome-flashback and turn the desktop off, then
caja -n --force-desktop can be used to provide a proper desktop
experience.
When using mutter all the title bars are Gnome-style... (click
for bigger)

With Compiz I could use mate-appearance-properties or other tools
to pick separate title bar and app themes, so at least generic
apps had the normal (to me) Ambiance title bars (which take up
less vertical space), with Mutter have to use the (buggy!) Gnome
Tweak tool to change the theme, only app themes can be selected.
Well.. at least the look is more consistent now. If I'm working I
can just run compiz --replace to go back to my old setup.
Yes that's the Microsoft Edge web browser(!) - it started out a
bit flaky but now it's pretty darn good (after enabling smooth
scrolling), basically it's like Chrome without the Google parts.
Edge (and Chrome) has a very nice feature - it can save pages in
PDF format with links preserved, I use it all the time to save
docs. I still prefer Firefox but I use it for Hulu Netflix etc so
needed a GP alternative browser I can resize differently.
Microsoft providing Edge for Ubuntu/Linux might be a start of a
new thing.. I remember when commercial software under Linux was
often a nightmare (and sometimes still is) - plastering extra
files all over my system, interfering with other apps etc - but
Edge gets it right.. adds its repository then installs and updates
like any other Ubuntu app.
Mutter Mutter...
3/27/21 - Well that didn't last long... VirtualBox running
Windows 7 is Extremely Unstable when running under the Mutter WM.
Too bad.. other than the title bars I really like Mutter,
especially when playing video. But back to Compiz for the most
part. Firefox and MPV don't seem to like Compiz, but got rid of
most of the bugginess by disabling all the Compiz plugins then
re-enabled a minimum of effects, basically just animations - it
helps to have a clue where a window minimizes to on the taskbar.
Better but Firefox still occasionally temporarily shows an empty
window or otherwise flashes, especially if it has been running for
awhile.
So I made a window manager chooser script...
--------------- begin SelectWM -----------------------
#!/bin/bash currentwm="Unknown" if pgrep -f metacity > /dev/null;then currentwm="Metacity";fi if pgrep -f compiz > /dev/null;then currentwm="Compiz";fi if pgrep -f mutter > /dev/null;then currentwm="Mutter";fi selection=$(zenity --title "Select WM" --hide-header \ --text "Currently using $currentwm" \ --column "" --list "Metacity" "Compiz" "Mutter") if [ "$selection" = "Metacity" ];then metacity --replace & fi if [ "$selection" = "Compiz" ];then compiz --replace & fi if [ "$selection" = "Mutter" ];then mutter --replace & fi if [ "$selection" != "" ];then sleep 1 zenity --title "Select WM" --info --width 200 --text "Changed to $selection" fi
--------------- end SelectWM -------------------------
Replacing a running window manager is a fairly invasive operation
so best to close apps first. Usually not, but sometimes Gnome
Panel gets confused about what's open or minimized and has to be
restarted. Since discovering VirtualBox's dislike for mutter
(hopefully that gets fixed!) I often use the script first just to
make sure I'm not using mutter.
5/2/21 - The last version of VirtualBox (6.1.22) appears to have
fixed the mutter crash issue.. at least it hasn't crashed under
Mutter since updating it. Or maybe it was a recent X-org update?
Or NVidia driver update? Still a bit cautious of the combination
but (despite messing with the title bars) Mutter is my preferred
WM at the moment - Firefox still bugs out bigtime with Compiz, MPV
doesn't particularly like it, both work great with Mutter. Just in
case I imported my Win7 work VM to VM-Ware Player as a backup in
case VirtualBox starts acting up again. Software interactions can
be tricky!
Floating Point Math in a shell script
I needed a script for a simple timer (actually so that I wouldn't burn my pizza) but it bugged me being limited to integer minutes.. be nice to enter 9.5 instead of having to choose 9 or 10. It's actually quite easy to do using awk...
--------------- begin minutetimer --------------------
#!/bin/bash # a simple timer.. enter minutes to delay then it pops up an # alert after that many minutes have passed. Floating point ok. minutes=$(zenity --title "Minute Timer" --width 300 --entry --text \ "Enter minutes to delay..." ) if (echo "$minutes"|grep " ">/dev/null);then minutes="";fi seconds="";if [ "$minutes" != "" ];then seconds=$(echo -|awk "{if ($minutes>0) {print $minutes*60}}") fi if [ "$seconds" = "" ];then zenity --title "Minute Timer" --width 300 --info --text \ "Not running." exit fi sleep $seconds zenity --title "Minute Timer" --width 300 --info --text \ "It's been $minutes minutes ($seconds seconds)"
--------------- end minutetimer ----------------------
The script uses zenity to get the number of minutes to delay,
checks to make sure the entry contains no spaces, and if something
was entered uses [g]awk to convert the entry to seconds but only
if a positive non-zero number was entered. If the seconds variable
is empty because of error or out of range then prints a "Not
running" message, otherwise sleeps the entered number of minutes
then pops up a message indicating that amount of time has passed.
The key math line is...
seconds=$(echo -|awk "{if ($minutes>0) {print $minutes*60}}")
...which sets seconds to minutes*60 but only if minutes>0,
otherwise the seconds variable is left empty. The echo - piped to
awk is simply a dummy line to give it something to do, echo
anything|awk works just as well. Because the code is within double
quotes variables are expanded but math symbols are not. Condition
codes for if can be < > <= >=
== or != for not equals (as usual == and != are usually not
appropriate for floating point comparisons), math codes are + - *
/ and ^ or ** for raising a number to a power. Math functions
include sin() cos() atan2() sqrt() exp() log() and rand(). See man
awk for more info.
Awk is an old programming language from the '70's that's
installed by default on most unix and linux systems. According to
Google Awk is
no longer used but that can't possibly be true, I just used
it (it's a joke answer from stack overflow). It's not exactly a
general purpose programming language (it's meant for text
processing and data manipulation), but it's nice for scripting
when fancier stuff is needed and I don't want to figure out how to
do it with another scripting language. Or worrying if my code will
be compatible with future versions, which is a nice advantage of
using a popular but "dead" language.
3/30/21 - A couple of cool programs I found that require
practically no installation...
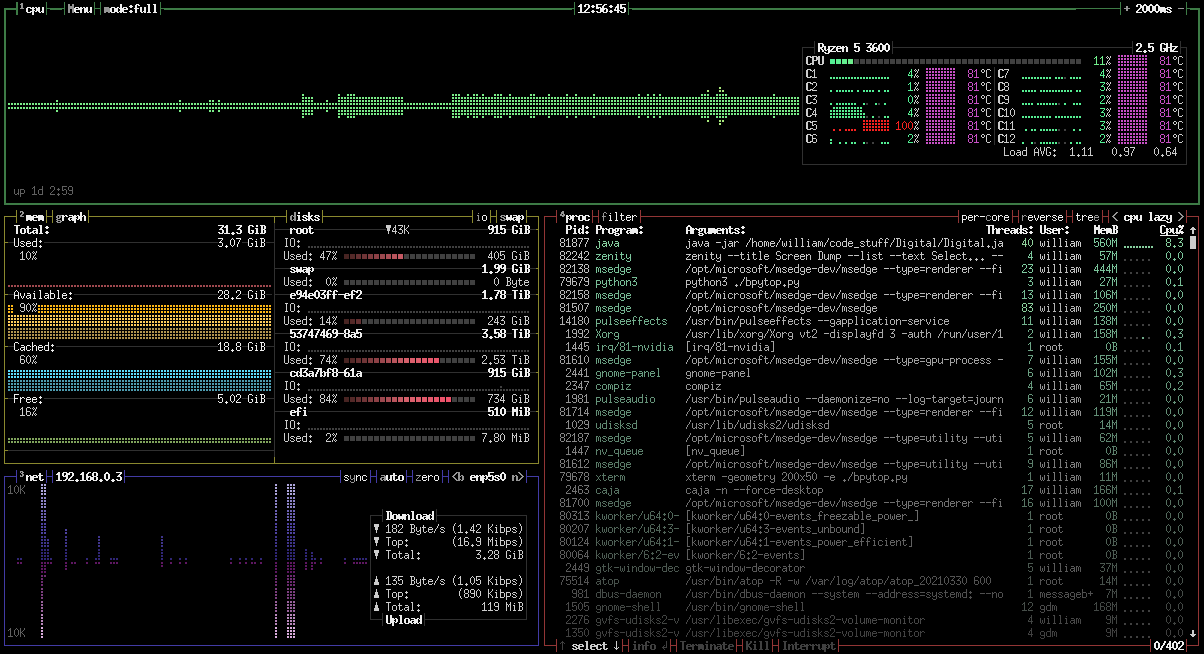
BPyTop is a
Python rewrite of a program called bashtop by the same author (one
of the coolest bash scripts I've ever seen), it's kind of like a
htop process lister that also provides memory, disk and network
status at a glance. The python version replaces the bash version
as it does about the same thing but with less overhead and has
mouse control. It dynamically adjusts the display to the terminal
dimensions, and for a terminal app looks super cool.
You can "install" it if you want (make install) but it runs just
fine from wherever it's unzipped to, simply run bpytop.py in a
terminal. It presents a lot of information so I run it in xterm
(which defaults to a small font) set to a fairly large window
using the following script placed in the program directory...
------------------- begin run_bpytop ---------------------
#!/bin/bash cd $(dirname "$0") xterm -geometry 200x50 -e ./bpytop.py
------------------- end run_bpytop -----------------------
...then run the script using a desktop shortcut and menu entry.
Digital is a
digital circuit simulator written in Java. I use Spice circuit
simulators such as LTSpice
and SIMetrix all the
time (both Windows programs but they run well under wine) but
Spice simulates circuits almost "down to the electron" and unless
you've got a supercomputer handy, aren't suitable for simulating
more than a few hundred components at a time. A digital logic
simulator like Digital is totally different and MUCH faster
because it deals only in logic - combinations of 0 and 1 that
produce outputs of 0 and 1. As far as I can tell it doesn't even
consider propagation delay so things like that have to be
calculated manually. Just about the only analog-like functions
supported by a digital simulator are pull-up and pull-down
resistors (without actual ohm values) and diodes for passive
logic. Digital does support individual mosfets but likely treats
them mostly as voltage-controlled switches rather than an actual
component simulation. For digital circuitry this is all just fine
and results in a massive speed-up and makes it practical to
simulate fairly large circuits at hundreds of kilohertz, fast
enough to watch the operation of a simulated processor in real
time. Other cool things about Digital is it includes a fairly wide
selection of common 74xx logic chips that can be wired up in
pictorial form (like the 2nd screenshot), and many of the elements
can be exported to Verilog/VHDL for converting to FPGA circuits.
Digital requires no system installation, simply download the
Digital.zip file linked from the github page, unzip it somewhere
and run the Digital.sh script (no terminal) to start the program.
Requires a Java runtime but usually that's already installed.
4/1/21 - I've been using Kate to colorize program code, which it
does fairly well but it's a manual process - have to load the file
then export to HTML. I wanted something more automatic, something
I could just copy/paste code into then it displays it in a web
browser so I can copy/paste the colorized code into the SeaMonkey
Composer web page editor. I had heard that the VIM editor was
scriptable, googled and found
this simple method: vim -c TOhtml -c wqa filename. The -c
option runs commands as if they were typed at the : prompt, TOhtml
converts the file to HTML and wqa writes the file then exits VIM.
Works great! Or I thought... after copy/pasting the code it's no
longer colorized. Copy/paste works fine with Kate's conversion so
examined the output of both Kate and VIM and found that VIM uses
class tags rather than in-line style tags. Another issue was VIM's
colors were not right for a white background and would change
depending on the terminal VIM was running in (if any). The class
tags in VIM's HTML output are convenient search and replace
targets so ran the HTML through a sed pipeline to change the class
tags to in-line style tags, that fixed the copy/paste problem and
the colors can be set to anything. For copy/pasting the code to
convert I would have prefered something like a text edit dialog
but I was surprised that a simple Zenity text prompt could swallow
several-hundred K of code just fine [aha.. Zenity has a multi-line
input dialog using the options --text-info --editable]. There was
still issues with copy/pasting the output - added extra preformat
fields that confused SeaMonkey Composer making it difficult to
edit the pasted code but that ended up being a Firefox thing -
works fine with Google Chrome or the chrome-based Microsoft Edge.
Using the script it didn't take long to colorize all the bash
code on this page, for each script I highlighted and copied the
code, ran VIMconvert, pasted the code and converted, then
copy/pasted the colorized code back to SeaMonkey composer, easy to
do as the code was still highlighted from the initial copy.
[sometimes] It still adds an extra pre field at the end but after
pasting I just press Delete to remove it (cursor is already
there), otherwise there are no odd editing effects. It did bloat
up the size of this page quite a bit but pretty sure the internet
can handle it.
Here's my hacked-together conversion script... [updated]
---------------- begin VIMconvert ------------------------
#!/bin/bash # VIMconvert 211007 (added yabasic seamonkey 211205) (tweaked css 230204) # requires zenity sed and a web browser # vimxterm yes setting requires xterm # Usage: VIMconvert [--save] [filename] # converts code to HTML using the VIM editor # if run with no file parameter then uses zenity to get the code, # if the pasted code doesn't start with #!/ then prompts for an # extension to use for syntax highlighting # use the --save option to save the html file to current directory # instead of opening a browser to display the code savehtml="no" # make "yes" to save html output file vimxterm="yes" # make "yes" to run vim in xterm tempname="/dev/shm/vimconvert_tmp" # path/basename for temp files # edit to specify web browser for viewing output... # browser="firefox" # firefox's copy/paste adds extra characters # browser="microsoft-edge" # lately edge has been causing issues # browser="google-chrome" # and so is chrome.. copy/paste loses color browser="seamonkey" # this works well when copy/pasting to seamonkey-composer browserparms="--new-window" # avoid opening a tab on existing instances browserprefix="file://" # prepended to the full file path # define colors/styles... (what I've noticed but might have missed some) css_Type="color:#006000;" css_Todo="color:#808080;background-color:#ffff00;padding-bottom:1px;" css_Identifier="color:#004040;" css_PreProc="color:#9020d0;" css_Statement="color:#952a2a;font-weight:bold;" css_Comment="color:#0000ff;" css_Constant="color:#ff00ff;" css_Special="color:#6a5a7d;" if [ "$1" = "--save" ];then savehtml="yes";shift;fi if [ -f "$1" ];then # if parm file exists tempname="$tempname($(basename "$1"))" # add the filename to tempname # adjust the temp name extension to include the file extension filename=$(basename "$1"|sed -e 's/\(.*\)/\L\1/') # get lowercase base name if (echo "$filename"|grep -q "\.");then # if file has an extension fileextension="${filename##*.}" # extract the extension tempname="$tempname.$fileextension" # add it to the tempname fi fi if [ -f "$tempname" ];then rm "$tempname";fi #remove temp if it exists if [ -f "$1" ];then # if parm file exists cp "$1" "$tempname" # copy it to the temp file else # otherwise prompt for code with zenity # this might require a more recent version of zenity # if it doesn't work use a simple entry prompt: --width 500 --entry script=$(zenity --title "VIMconvert - paste code to convert" \ --width 500 --height 500 --ok-label "Convert" --text-info --editable ) if [ "$script" != "" ]; then # if code was entered echo "$script" > "$tempname" # write it to a file if (head -n 1 "$tempname"|grep -vq "^#!/");then # no #!/, prompt for ext fileextension=$(zenity --title VIMconvert --width 500 --entry --text \ "Enter a file extension (without the .) for syntax highlighting...") if [ "$fileextension" != "" ];then # if an extension was entered mv -f "$tempname" "$tempname.$fileextension" # move file to new name tempname="$tempname.$fileextension" # adjust tempname variable fi fi fi fi if [ -f "$tempname" ];then # if temp file exists then # adjust extension for custom interpreter files... firstline=$(head -n 1 "$tempname"|grep "^#!/") newext="" if (echo "$firstline"|grep -q "blassic");then newext=".bas";fi if (echo "$firstline"|grep -q "fbcscript");then newext=".bas";fi if (echo "$firstline"|grep -q "brandy");then newext=".bas";fi if (echo "$firstline"|grep -q "bbcscript");then newext=".bas";fi if (echo "$firstline"|grep -q "baconscript");then newext=".bas";fi if (echo "$firstline"|grep -q "yabasic");then newext=".bas";fi if (echo "$firstline"|grep -q "cwrapper");then newext=".c";fi # detect old-style BASIC code - match first line = number COMMAND firstline=$(head -n 1 "$tempname"|grep -E "^ {,4}[0-9]{1,5} {1,4}[A-Z]") if (echo "$firstline"|grep -Eq \ " REM| PRINT| LET| IF| DIM| INPUT| READ| FOR| GOTO| GOSUB" \ );then newext=".bas";fi if [ "$newext" != "" ];then mv -f "$tempname" "$tempname$newext" tempname="$tempname$newext" fi # run the vim command to convert the temp file to HTML... vimcmdprefix="";if [ "$vimxterm" = "yes" ];then vimcmdprefix="xterm -e";fi $vimcmdprefix vim -c TOhtml -c wqa "$tempname" < /dev/null if [ -f "$tempname.html" ];then # if the command succeeded # VIM's output uses class tags and color information is lost when # copy/pasted from a browser window, so use a sed pipeline to change # the class tags to in-line style tags using script-assigned colors mv -f "$tempname.html" "$tempname.html.tmp" < "$tempname.html.tmp" \ sed -e "s/<span class\=\"Type\">/<span style\=\"$css_Type\">/g"\ |sed -e "s/<span class\=\"Todo\">/<span style\=\"$css_Todo\">/g"\ |sed -e "s/<span class\=\"Identifier\">/<span style\=\"$css_Identifier\">/g"\ |sed -e "s/<span class\=\"PreProc\">/<span style\=\"$css_PreProc\">/g"\ |sed -e "s/<span class\=\"Statement\">/<span style\=\"$css_Statement\">/g"\ |sed -e "s/<span class\=\"Comment\">/<span style\=\"$css_Comment\">/g"\ |sed -e "s/<span class\=\"Constant\">/<span style\=\"$css_Constant\">/g"\ |sed -e "s/<span class\=\"Special\">/<span style\=\"$css_Special\">/g"\ > "$tempname.html" rm "$tempname.html.tmp" htmlpath=$(readlink -f "$tempname.html") # get the full path/filename if [ "$savehtml" = "yes" ];then # if save option specified savename="." # default same as temp name in the current dir if [ -f "$1" ];then savename="$1.html";fi # if file exists use file.html cp "$htmlpath" "$savename" else # display the converted code with a web browser "$browser" $browserparms "$browserprefix$htmlpath" & sleep 7 # allow time to load before deleting temp files # if problems with load time remove the & from the browser command fi rm "$tempname.html" fi if [ -e "$tempname" ];then rm "$tempname";fi fi
---------------- end VIMconvert --------------------------
[ note - the browser for viewing the output is set to SeaMonkey
because that's the only one that seems to work properly, see the
comments in the script ]
Currently I use the script as a Caja script so I can right-click a file to convert it, or run the script with no parameters to copy/paste code. Can be used from a terminal, or associate text files to it to add VIMconvert as an open with option. By default it doesn't save the converted HTML, add --save to the command line to save the converted HTML file. To make it always save the HTML edit the script to change savehtml="no" to savehtml="yes". The colors can be changed as desired. There might be more class tags, if a tag is missing then the color will look right in the browser but the affected code items will not be colorized after copy/pasting. I didn't figure out how to specify the syntax scheme on the command line but VIM goes by either the #!/ header or the file extension, so preserved the extension when making the temp file. When copy/pasting code if no #!/ header is present then it prompts for an extension to use for syntax highlighting. I use a few BASIC-like #!/ interpreters so there's a section to detect them and change the extension, edit as needed.
VIM's BASIC converter usually works ok enough but it has a couple
issues I'd like to fix if possible - it parses \" as an escaped
quote like in bash, but that messes up some BASIC code, like PRINT
"/!\" which causes all further code to be misconverted. Also REM
works but rem does not show as comment code. Something else to
figure out. For just about everything else I've tried it seems to
work fine. It's a fairly complicated script so there are probably
bugs.. one bug I just fixed was it wasn't checking to see that
class="etc" was actually part of a span tag, potentially changing
program code.. does the full check now.
4/2/21 - Fixed another bug, goofed up the code for extracting the
file extension. Shellcheck (handy utility!) was complaining about
a useless cat in the sed pipeline (habit) so replaced it with
redirection, now it's one of the few non-trivial scripts I've made
that shellcheck doesn't give at least green warnings (not that
that means much, it doesn't check for logic bugs). Removed the
spaces from the style strings. Now uses /dev/shm/ instead of /tmp/
for temp files to avoid writing, that seems to be fairly standard
now - if /dev/shm/ doesn't exist edit the script to use /tmp/
instead. Removed an unneeded sleep 1 after the conversion, left
over from trying to use gvim instead of vim. Made it so that the
--save option does not launch a web browser and immediately exits,
making it faster (and possible) to use for batch conversion using
a command line like: for f in *;do VIMconvert --save "$f";done
(assumes VIMconvert is in a path dir and that all the files are
text - the script will output garbage if passed binary code but it
doesn't crash and embedded strings still show). Unless the --save
option is used, as written the VIMconvert script doesn't write
anything to the current directory. The script does a fair amount
of temp file manipulation to adjust the extension (so far that's
the only way I know how to tell VIM what kind of file it is),
changed the cp/rm's to mv -f to make it a bit faster, the -f to
make sure it doesn't fail if the file exists from a crash etc.
--------------- begin VIMconvert_save ------------------
#!/bin/bash scriptdir=$(dirname "$0") "$scriptdir/VIMconvert" --save "$1"
--------------- end VIMconvert_save --------------------
...assumes that VIMconvert is in the same directory as
VIMconvert_save. With this script I can highlight a file,
right-click Scripts VIMconvert_save and the .html file appears
next to it. For pasted code (no filename specified) then it saves
the file using the temp filename.
It's still probably a work in progress but it's getting there,
it's very nice to finally have an easy way to colorize code. Just
need to fix the BASIC syntax thing. And resist the urge to monkey
with it unless it's actually broke, but that's me. I learned a few
tricks from making this script - using sed to lowercase a string,
extracting a file extension, multi-line Zenity text input, and a
bit about VIM. Still can't get on board with using VIM as an
actual editor but it certainly does handy stuff.
4/6/21 - Figured out a bit about VIM's syntax file format, enough
to reasonably colorize the BASIC code on this page and other BASIC
code I typically work with. Figuring out the VIM docs is tedious
but the basics are starting to sink in. The HTML docs are much
better as the needed info tends to be scattered across different
files. At first was editing the installed basic.vim file but
figured out I was supposed to put altered syntax files in my home
.vim/syntax directory, had to create it.
From the altered comments...
" Mods by WTN 2021/4/6...
" added Rem rem, REM now requires trailing space, fixed ' so it can appear after code
" added statement keywords - ENDWHILE ENDIF OSCLI OFF COLOUR REPORT QUIT AS OUTPUT APPEND
" added statement keywords - BINARY RANDOM TO CHR AND OR NOT UNTIL ELSEIF WITH REPEAT
" added function keywords - LCASE UCASE LEFT RIGHT MID LTRIM RTRIM STR INKEY SPACE GETKEY
" added types - INTEGER LONGINT DOUBLE FLOAT STRING ANY PTR POINTER PIPE BYVAL BYREF
" removed escape skipping from strings (so PRINT "\" doesn't mess it up)
" removed AND/OR from math symbols matching (was highlighting embedded text)
" added detection for labels: and blassic's label, changed link for basicLabel
" added matches for line numbers with leading spaces
" added detection for #directives and initial #!/ interpreter line
This modified basic.vim seems to
work fairly well for QBasic, FreeBasic, BBC Basic, Blassic,
minicomputer HPBASIC and other similar dialects, at least it's
MUCH better than it was. It doesn't include all of the extra
Blassic, BBC Basic and FreeBasic keywords, just the ones I use and
noticed in other code - it's a work in progress, will add to it if
needed. Also not attempting to distinguish between different types
of BASIC as that would require tricky type detection etc, so don't
want to get too specific with the highlighting. My hacks are
likely not optimal, mostly tinkered with it until it did what I
wanted or something that was close enough.
4/7/21 - slight update to VIMconvert, was going through fixing up
code on my previous ubstuff.html page
and added a couple of lines to handle cwrapper and baconscript scripts. BaCon is a BASIC to
C converter, baconscript is a simple script that invokes the
compiler and runs BaCon code from a prepended #!/ line. The
cwrapper does a similar thing using gcc to compile and run C code.
I don't use either one very much but BaCon is neat, would like to
get into it more. The VIMconvert script fakes baconscript using a
.bas extension, the modified basic.vim file handles simple bacon
code reasonably well which for scripting is about all I'd be doing
anyway, otherwise I'd fire up the BaCon GUI IDE and do it right.
The bacon.vim syntax file included with the tar.gz source does a
much better job, to enable it for .bac files copy bacon.vim to
~/.vim/syntax and make a ~/.vim/ftdetect directory and put a file
in it named "ftbacon.vim" (actually can be named anything.vim)
containing a single line...
au BufRead,BufNewFile *.bac set filetype=bacon
Only needed a couple keywords in the basic.vim file to make my
simple code look right, otherwise BaCon is way too different to
support in a common BASIC syntax file, the thing can be used to
make GTK apps and stuff. With bacon.vim and ftbacon.vim installed
as described above, right-clicking a .bac file and running the
VIMconvert script will properly colorize the code.
Another reason I downloaded BaCon was to test VIMconvert using the almost-500K bacon.sh script - I noticed some syntax coloring errors on some bash code - sometimes it gets confused and fails to highlight if else fi etc but only happens with tricky code, bacon.sh looks fine. The bashtop bash script triggers it right after the line...
hex2rgb=${hex2rgb//#/}[...]
4/9/21 - The bash syntax glitches doesn't seem too widespread -
the { # } glitch only happens if unquoted. Noticing other glitches
like failure to detect _EOF after a <<_EOF_, for example in
winetricks. [newer sh.vim fixes this and the comment bug see
below]
Minor updates to VIMconvert - added the base filename (in
parenthesis) to the temp filename. While going through stuff I
found myself having to go back to the file manager to see what
file I just processed. Added a vimxterm script setting to run the
vim command in xterm to show export progress, to prevent keyboard
interference stdin is redirected from /dev/null.
4/11/21 - Pretty much all of the bash/sh highlight bugs I noticed
with the stock v188 file are fixed with "Dr.
Chip's" new
sh.vim file. Solved, just copy it to the ~/vim/syntax
directory. The only remaining things I notice are a few spurious
error highlights which are for all I know are actual errors - my
VIMconvert script doesn't process error tags so they will be
copied as monochrome. Added the line let g:sh_no_error = 1 to my
vim.sh to disable error detection - that feature would be useful
when composing code in VIM (which I don't do) but annoying when
viewing/posting existing code.. I just want syntax highlighting.
4/16/21 - Added a bit of code to VIMconvert so it would recognize
old-style BASIC in a text file. Fun with grep! To be recognized as
BASIC the first line must start with a 1 to 5 digit number with no
more than 4 leading spaces followed by 1 to 4 spaces followed by a
capital letter, and must contain one of the commands listed in the
secondary grep. This is mainly for papertape BASIC listings for
'70's-era HP minicomputers which I tend to save as *.txt because
that BASIC is very different from QBasic etc. Also a minor change
to basic.vim, some of those old programs use REM-COMMENTS with no
space after REM.
5/2/21 - The new sh.vim still has rare issues... it does not like
this code from Rebs...
bottomleftcorner="\`" bottomrightcorner="'" horizontalchar="-"
[....]
# input: $data $datatweekchance $size $maxnegdata plus getdata's reqs # output: modified $data if [ $RANDOM -lt $datatweekchance ]; then
... and remains in the weeds until the next function. Escaping
the quoted ' in the 2nd line makes it worse, then it doesn't
recover at all. Not quite sure yet if that's really a highlight
bug or semi-ambiguous bash code; although it feels like a
highlight bug (bash is fine with it), putting literal ` and '
characters in double-quote strings (escaped or not) is almost
asking for order-of-evaluation problems. Replacing "\`" with
"\140" and "'" with "\047" produces the same run-time results
without possible unclosed shell or single-quote side-effects.
5/15/21 - I tried VIMconvert on my Pascal code but the results
were a mess. Very easy to fix though, just added detection for //
comments by adding a single line after the existing comment
definition...
syn region pascalComment start="//" end="$"
Also added another simple line to detect the Try and Except
keywords. Here's a zip containing the modified
pascal.vim file. Also includes a ftdetect file for .pp
files, an extension used by some of the demo programs included
with Free Pascal. Will update if needed but seems to work OK, used
it to reconvert the Pascal code on this page - Kate does a good
job making stand-alone HTML files from source but copy/pasting the
code into another web page (like this page) causes editing
glitches (like a browser-wide grey background that I don't want).
VIMconvert is easier and the resulting colors match the other code
here.
2/4/23 - Updated the VIMconvert script to the latest one I'm
using, not much was changed just added detection for yabasic code
(if there's a "#!/" line containing yabasic), tweaked the CSS
settings to make some of the colors a bit darker, and as written
it uses SeaMonkey for the browser - Firefox Crome etc were not
working for me. Firefox almost works but does a funny thing at the
beginning of the listing that adds an extra line that's hard to
edit out in SeaMonkey Composer (yes that is still my main HTML
editor, it works fine). Chrome and derivitives strip out html
color information when copying, which makes sense for copying code
from a web site but when using SeaMonkey for the browser copied
code comes out normal when pasted to a text editor, and preserves
the color when pasted to Composer. I don't think this is a
SeaMonkey-specific thing since Firefox behaves the same way and I
would use that if not for the formatting issue. As usual with the
scripts here, YMMV this is just how I do it.
FBCScript - Using FreeBasic as a
Scripting Language
Everyone seems to have an opinion of what's the best script-like
language when something gets too unwieldy for bash/sh... most are
not for me. Python - which version will someone have? Significant
whitespace? no way. No issue with the language, I use lots of
great stuff written in Python, just never really learned the
language and too much thinking when I just want to solve some
problem. Perl (5) - probably a better choice than Python for
script-like programs and although I've worked on perl programs
it's also another programming language I never really learned. An
issue with using almost all general purpose programming languages
for scripting is they are often as unwieldy and doing shell-like
tasks as shell is doing program-like tasks.
For me, the solution is BASIC - I know it without having to
reference anything, it has good string handling and text
processing abilities and when I do need to run shell commands it's
not that hard - usually just shell "commands" for simple stuff.
Capturing the output usually involves redirecting to a file then
opening it but used to it. For awhile I used Blassic for my
scripted BASIC needs but that interpreter isn't maintained anymore
and the file commands are non-standard so still found myself
having to look it up. I prefer good old fashioned QBasic but the
old Dos version doesn't support long filenames and the overhead of
loading DosEmu or DosBox is way too heavy for casual scripting.
Instead for the last year or so I've been using Free Basic as a
scripting language because the compiler is quite fast with a
minimum of fuss and if something is wrong with the code emits
useful error messages.
The following script is a very minor modification of my previous fbcscript script, the
only change is the temp directory is now on /dev/shm to avoid
writing disk files. To use, install Free Basic and copy the
following fbcscript file to /usr/local/bin (or another directory,
examples assume /usr/local/bin) and make executable etc, refer to
the original description for more info.
-------------- begin fbcscript --------------------------
#!/bin/bash # # fbcscript - make freebasic programs run like scripts - 210412 # # Copyright 2020-2021 William Terry Newton, All Rights Reserved. # This file is supplied as-is and without any warranty. # Permission granted to distribute with or without modification # provided this copyright notice remains reasonably intact. # # Copy this to (say) /usr/local/bin (otherwise adjust examples) # At the beginning of freebasic scripts add the line... # #!/usr/local/bin/fbcscript # ...to compile and run qbasic-style code. # To specify fbc options add --fbcopts followed by options (if any) # To run native freebasic code with no options... # #!/usr/local/bin/fbcscript --fbcopts # To run native freebasic code with the threadsafe library... # #!/usr/local/bin/fbcscript --fbcopts -mt # To use the fblite dialect... # #!/usr/local/bin/fbcscript --fbcopts -lang fblite # # Normally it refuses to run if not running in a terminal so # compile errors can be seen and that's what's usually wanted. # To bypass this check include --notermcheck first, as in... # #!/usr/local/bin/fbcscript --notermcheck [--fbopts [options]] # This only makes sense for graphical programs. # # If the compiled program exits normally (generally via system) # then the temporary files are automatically removed, however if # the terminal window is closed before the program terminates then # the temp .bas and .bin files will be left behind in the .fbcscript # directory. FB programs are usually small so this isn't much of # a concern and it doesn't interfere with operation, plus it's # an easy way to grab the compiled binary if needed. Periodically # clean out the .fbcscript directory if desired. # # Note... the script file must be in unix format (as with any # script interpreter called using the #! mechanism) # fbcscriptdir="/dev/shm/.fbcscript" # directory used for temp compiles compileopts="-lang qb -exx" # default fbc compile options titleterminal="yes" # attempt to title window according to script name if [ "$1" = "" ];then # if called without any parms at all print usage echo "fbcscript - runs freebasic code like it was script code" echo "To use add #!$0 to the beginning of the program" echo "and make the file executable. Default fbc options: $compileopts" echo "add --fbcopts followed by options (if any) to change defaults." echo "add --notermcheck first to bypass the terminal check." exit fi bangparms="$1" # either script name or extra parameters if (echo "$1"|grep -q "^--notermcheck");then # bypass terminal check bangparms=$(echo "$1"|tail -c +15) # remove from bangparms if [ "$bangparms" = "" ];then # if that was the only parm shift # to put the script name in $1 fi else # check for terminal if [ ! -t 1 ];then # if no terminal then exit # only alerts if zenity installed, if not just exits zenity --error --text="This program must be run in a terminal" exit fi fi fbcopts=$(echo "$bangparms"|grep "^--fbcopts") if [ "$fbcopts" != "" ];then compileopts=$(echo "$bangparms"|tail -c +11) # grab desired options shift # remove added parameter fi scrfile="$1" # should be the full name of script file shift # shift parms down to supply the rest to the program if [ -f "$scrfile" ];then # if the script exists mkdir -p "$fbcscriptdir" # make compile dir if it doesn't exist scrbasename=$(basename "$scrfile") # get base script filename scrname="$fbcscriptdir/$scrbasename" # prepend fbcscriptdir to base name head -n 1 "$scrfile" | if grep -q "#!";then # if code has a shebang line echo "'" > "$scrname.bas" # keep line count the same for errors tail -n +2 "$scrfile" >> "$scrname.bas" # append lines 2 to end else cp "$scrfile" "$scrname.bas" # copy code as-is fi # compile the script... if [ -f "$scrname.bin" ];then rm "$scrname.bin" # remove binary if it exists fi fbc $compileopts -x "$scrname.bin" "$scrname.bas" if [ -f "$scrname.bin" ];then # if compile successful if [ "$titleterminal" = "yes" ];then # if titleterminal enabled echo -ne "\033]2;$scrbasename\a" # try to change the window title fi "$scrname.bin" "$@" # run with original parameters rm "$scrname.bin" # remove temp binary else if [ -t 1 ];then # if running in a terminal echo "----- press a key -----" read -n 1 nothing # pause to read error messages fi fi rm "$scrname.bas" # remove temp source else # bad parm on the #! line if [ -t 1 ];then echo "Invalid option: $scrfile" echo "----- press a key -----" read -n 1 nothing fi fi exit # changes... # 200511 - initial version. # 200512 - added error message and pause for bad #! option. # 200512B - separated out script base name and used to set the # terminal window title using an escaped print. Seems to work # but if it causes problems change titleterminal to no. # 210412 - changed temp dir to /dev/shm/ to avoid disk writes
-------------- end fbcscript ----------------------------
Here's a fun little fbcscript program I made called
"benfordscan", it parses a file to see if the numbers in a file
follow Benford's
law... [updated 8/28/21]
-------------- begin benfordscan.fbc --------------------
#!/usr/local/bin/fbcscript --notermcheck ' benfordscan.fbc 210828 ' This FreeBasic (fbc -lang qb) program scans a text file and counts ' the occurances of the first digits of numbers, ignoring leading zeros ' and decimal points. This is often used to validate documents containing ' numerical data to see if the distribution follows "Benford's Law" where ' the first digits of real-world numbers spanning several magnitudes tend ' to be weighted towards the lower digits. Fabricated data tends to have ' a more random distribution. filename$=command$(1) 'filename in first parameter dim numbers(9) for i=1 to 9:numbers(i)=0:next i open filename$ for input as #1 while not eof(1) line input #1,a$ numflag=0 for i=1 to len(a$) b$=mid$(a$,i,1) if b$>="1" and b$<="9" then if numflag=0 then 'first digit n=val(b$) numbers(n)=numbers(n)+1 numflag=1 end if else if b$<>"0" and b$<>"." then numflag=0 end if next i wend close totalcount=0 for i=1 to 9 totalcount=totalcount+numbers(i) next i if totalcount=0 then print "No numbers found" else print "First digit number counts:" for i=1 to 9 print i,numbers(i) next i print "Normalized distribution:" for i=1 to 9 print i;" "; percent=(numbers(i)/totalcount)*100 print left$(str$(percent+0.0005),5);" "; z=int(percent/2) if z>0 then for j=1 to z print "*"; next j end if print next i end if system
-------------- end benfordscan.fbc ----------------------
(the --notermcheck in the #! line tells fbcscript to not check
for a terminal so that the output can be redirected if desired)
Example output for a large text file containing numbers that do
approximately follow Benford's law...
First digit number counts:
1 14551
2 7813
3 3648
4 2478
5 2095
6 2292
7 1697
8 1686
9 1447
Normalized distribution:
1 38.5 *******************
2 20.7 **********
3 9.67 ****
4 6.57 ***
5 5.55 **
6 6.07 ***
7 4.50 **
8 4.47 **
9 3.83 *
The benfordscan.fbc script can only process text files and does
not launch its own terminal, so I run it using a helper script...
[updated 8/28/21]
-------------- begin benfordscan ------------------------
#!/bin/bash # benfordscan 210828 - script for calling benfordscan.fbc # benfordscan.fbc must be in the same directory as this script # requires the pdftotext utility for scanning PDF files, # unzip for unpacking zip docx and xlsx files, and # the strings utility for isolating strings from binary data # relaunches itself in xterm unless 2nd parm is doit if [[ "$2" = "doit" ]]||[[ -t 1 ]];then thisfile=$(readlink -e "$0") scriptdir=$(dirname "$thisfile") tempname="/dev/shm/benfordscan.tmp" fname="$1" if [ -f "$fname" ];then echo "Scanning file $(basename "$fname")" if (echo "$fname"|grep -q ".pdf\$");then echo "(converting to text)" pdftotext "$fname" "$tempname.1" elif (echo "$fname"|grep -q ".zip\$");then echo "(extracting)" unzip -c "$fname" > "$tempname.1" elif (echo "$fname"|grep -q ".docx\$");then echo "(extracting)" unzip -c "$fname" > "$tempname.1" elif (echo "$fname"|grep -q ".xlsx\$");then echo "(extracting)" unzip -c "$fname" > "$tempname.1" else cat "$fname" > "$tempname.1" fi strings -n 1 "$tempname.1" > "$tempname" "$scriptdir/benfordscan.fbc" "$tempname" rm "$tempname.1" rm "$tempname" if [[ "$2" = "doit" ]]&&[[ -t 1 ]];then echo -n "--- press a key --- " read -rn 1 echo fi fi else xterm -e "$0" "$1" doit fi
-------------- end benfordscan --------------------------
The script checks the filename extension and if .pdf extracts the
text using the pdftotext utility, or if .zip .docx or .xlsx then
uses the unzip utility to extract the contents to a single file.
After extracting or not, uses the strings utility to extract ascii
text from the file so that it will work better with binaries. Uses
/dev/shm/ for temp files which on modern systems is a ram disk, if
that doesn't work can use "/tmp/" or any writable directory.
Not related to fbcscript but making terminal scripts work right
whether or not they are run from a terminal is a bit tricky..
checking for an interactive terminal precludes redirection and can
possibly result in an infinite loop of spawns if for any reason
the terminal check fails, so uses a "doit" flag to make sure that
can't happen. But then it launches in xterm anyway if already in a
terminal. So the helper script uses a dual approach.. if in a
terminal doesn't spawn an xterm, and only prints the "--- press a
key ---" prompt if launched in xterm and also in an interactive
terminal. Still doesn't handle redirection though unless "doit" is
added to the command line after the filename - not going to
complicate this toy to try to detect something I'd likely never
want to do anyway - main reason for the extra checks are to avoid
infinite loops or hangs in case of bugs or being accidentally
redirected, similar to what I do for most of my scripts that might
or might not be running from a terminal.
The following scripts have to be run in a terminal, they are
conversions of programs that were originally written using
Blassic.
Here's a hex to UTF-8 converter for converting Unicode code
points into byte sequences...
-------------- begin hex2utf8.fbc -----------------------
#!/usr/local/bin/fbcscript 'hex2utf8.fbc - converts hex unicode to UTF encoded bytes - 200511 'prompts for hex string for a unicode character (often stated as U+somehex, 'don't enter the U+ part, just the hex) then prints the encoded byte 'sequence in decimal and hex and displays the character (if possible). 'Loops until 0 or an empty string is entered. 'fbscript version - uses fbscript to temporarily compile and run 'using the freebasic compiler (fbc -lang qb -exx) color 15,1:cls print "*** Unicode to UTF-8 ***" dim bytenum(4) again: input "Unicode hex string: ",a$ n=int(val("&h"+a$)) if n<=0 then goto programend if n>55295 and n<57344 then goto badnumber if n<128 then goto onebyte if n>127 and n<2048 then goto twobyte if n>2047 and n<65536 then goto threebyte if n>65535 and n<1114112 then goto fourbyte badnumber: print "Invalid code":goto again onebyte: nbytes=1 : bytenum(1)=n goto showresults twobyte: nbytes=2 bytenum(1)=192+(n AND 1984)/64 bytenum(2)=128+(n AND 63) goto showresults threebyte: nbytes=3 bytenum(1)=224+(n AND 61440)/4096 bytenum(2)=128+(n AND 4032)/64 bytenum(3)=128+(n AND 63) goto showresults fourbyte: nbytes=4 bytenum(1)=240+(n AND 1835008)/262144 bytenum(2)=128+(n AND 258048)/4096 bytenum(3)=128+(n AND 4032)/64 bytenum(4)=128+(n AND 63) showresults: print "Decimal "; for i=1 to nbytes print bytenum(i); next i : print print "Hex "; for i=1 to nbytes print right$("0"+hex$(bytenum(i)),2);" "; next i : print print "Display "; for i=1 to nbytes print chr$(bytenum(i)); next i : print goto again programend: system
-------------- end hex2utf8.fbc -------------------------
Example output...
*** Unicode to UTF-8 ***
Unicode hex string: 2523
Decimal 226 148 163
Hex E2 94 A3
Display ┣
Unicode hex string: 2524
Decimal 226 148 164
Hex E2 94 A4
Display ┤
Unicode hex string:
Here's a program for finding the closest stock resistor value...
-------------- begin closestR.fbc -------------------------
#!/usr/local/bin/fbcscript rem a program for finding standard resistor values rem by WTN, last mods 20180117 20210412 color 15,1:cls print "=== Resistor Value Finder ===" print "Finds the closest stock 1% and 5% resistor values." print "Entry can include K or M suffix, output is standard" print "resistor notation. Enter an empty value to exit." dim valueE96(97),valueE24(25) rem E96 values, extra decade value at the end to simplify code data 100,102,105,107,110,113,115,118,121,124,127,130,133,137 data 140,143,147,150,154,158,162,165,169,174,178,182,187,191 data 196,200,205,210,215,221,226,232,237,243,249,255,261,267 data 274,280,287,294,301,309,316,324,332,340,348,357,365,374 data 383,392,402,412,422,432,442,453,464,475,487,499,511,523 data 536,549,562,576,590,604,619,634,649,665,681,698,715,732 data 750,768,787,806,825,845,866,887,909,931,953,976,1000 for i=1 to 97:read valueE96(i):next i rem E24 values+decade data 10,11,12,13,15,16,18,20,22,24,27,30 data 33,36,39,43,47,51,56,62,68,75,82,91,100 for i=1 to 25:read valueE24(i):next i entervalue: line input "Desired value: ",desired$ desired$=ltrim$(rtrim$(ucase$(desired$))) if desired$="" then goto exitprogram mult=1:num$=desired$ if right$(desired$,1)="K" then mult=1000:num$=left$(num$,len(num$)-1) if right$(desired$,1)="M" then mult=1000000:num$=left$(num$,len(num$)-1) rem blassic's val() ignores trailing invalid characters so validate manually rem num$ must contain only 0-9 and no more than one decimal point E=0:E1=0:PC=0 for i=1 to len(num$) a$=mid$(num$,i,1) if asc(a$)<asc("0") or asc(a$)>asc("9") then E1=1 if a$="." then E1=0:PC=PC+1 if E1=1 then E=1 next i if E=0 and PC<2 then goto entryok print "Don't understand that, try again" goto entervalue entryok: rem calculate desired value from string and multiplier desiredR=val(num$)*mult if desiredR>=0.1 and desiredR<=100000000 then goto valueok print "Value must be from 0.1 to 100M" goto entervalue valueok: rem determine multiplier to convert stored values norm=0.001 if desiredR>=1 then norm=0.01 if desiredR>=10 then norm=0.1 if desiredR>=100 then norm=1 if desiredR>=1000 then norm=10 if desiredR>=10000 then norm=100 if desiredR>=100000 then norm=1000 if desiredR>=1000000 then norm=10000 if desiredR>=10000000 then norm=100000 rem determine lower value match, upper match is one more rem compare to a slightly smaller value to avoid FP errors for i=1 to 96 if desiredR>valueE96(i)*norm-0.00001 then v1=i:v2=i+1 next i lowerE96=valueE96(v1)*norm upperE96=valueE96(v2)*norm rem do the same for E24 series, using norm*10 since E24 values are 2 digit for i=1 to 24 if desiredR>valueE24(i)*norm*10-0.00001 then v1=i:v2=i+1 next i lowerE24=valueE24(v1)*norm*10 upperE24=valueE24(v2)*norm*10 rem calculate error percentages for lower and upper values lowerE96error=(1-lowerE96/desiredR)*100 upperE96error=-(1-upperE96/desiredR)*100 lowerE24error=(1-lowerE24/desiredR)*100 upperE24error=-(1-upperE24/desiredR)*100 rem determine which value has less error rem in the event of a tie go with the higher value (user can pick) closestE96=lowerE96:if lowerE96error>=upperE96error then closestE96=upperE96 closestE24=lowerE24:if lowerE24error>=upperE24error then closestE24=upperE24 rem print the closest value and error percentages for lower/upper values print "Closest E96 value = "; R=closestE96:gosub convertE96:print R$;space$(7-len(R$));"("; rem to detect exact matches compare to a range to avoid float errors M=0:if closestE96>desiredR-0.0001 and closestE96<desiredR+0.0001 then M=1 if M=1 then print "exact match)":goto printE24values E$=left$(ltrim$(str$(lowerE96error+0.0001)),4) R=lowerE96:gosub convertE96:print "-";E$;"%=";R$;","; E$=left$(ltrim$(str$(upperE96error+0.0001)),4) R=upperE96:gosub convertE96:print "+";E$;"%=";R$;")" printE24values: print "Closest E24 value = "; R=closestE24:gosub convertE24:print R$;space$(7-len(R$));"("; M=0:if closestE24>desiredR-0.0001 and closestE24 < desiredR+0.0001 then M=1 if M=1 then print "exact match)":goto doneprintingvalues E$=left$(ltrim$(str$(lowerE24error+0.0001)),4) R=lowerE24:gosub convertE24:print "-";E$;"%=";R$;","; E$=left$(ltrim$(str$(upperE24error+0.0001)),4) R=upperE24:gosub convertE24:print "+";E$;"%=";R$;")" doneprintingvalues: goto entervalue:rem loop back to enter another value exitprogram: system rem subroutines to convert R value back to standard notation rem input R containing resistor value (with possible float errors) rem output R$ containing value in standard resistor notation convertE96: R$="error":R2$="":R1=R+0.00001:R2=R if R1>=1000 then R2=R1/1000:R2$="K" if R1>=1000000 then R2=R1/1000000:R2$="M" if R2<1 then R$=left$(ltrim$(str$(R2+0.00001))+"000",5) if R2>=1 and R2<100 then R$=left$(ltrim$(str$(R2+0.00001))+"000",4)+R2$ if R2>=100 and R2<1000 then R$=left$(ltrim$(str$(R2)),3)+R2$ return convertE24: R$="error":R2$="":R1=R+0.00001:R2=R if R1>=1000 then R2=R1/1000:R2$="K" if R1>=1000000 then R2=R1/1000000:R2$="M" if R2<1 then R$ = left$(ltrim$(str$(R2+0.00001))+"00",4) if R2>=1 and R2<10 then R$=left$(ltrim$(str$(R2+0.00001))+"00",3)+R2$ if R2>=10 and R2<100 then R$=left$(ltrim$(str$(R2)),2)+R2$ if R2>=100 and R2<1000 then R$=left$(ltrim$(str$(R2)),3)+R2$ return
-------------- end closestR.fbc ---------------------------
Example output...
=== Resistor Value Finder ===
Finds the closest stock 1% and 5% resistor values.
Entry can include K or M suffix, output is standard
resistor notation. Enter an empty value to exit.
Desired value: 1700
Closest E96 value = 1.69K (-0.58%=1.69K,+2.35%=1.74K)
Closest E24 value = 1.6K (-5.88%=1.6K,+5.88%=1.8K)
Desired value: 74k
Closest E96 value = 73.2K (-1.08%=73.2K,+1.35%=75.0K)
Closest E24 value = 75K (-8.10%=68K,+1.35%=75K)
Desired value:
I still have quite a few more Blassic "scripts" I still use and
need to convert to fbcscript as Free Basic is actively developed,
Blassic barely even compiles anymore. There still is a need for a
compact BASIC interpreter like Blassic that "just works" and
doesn't need much in the way of installing (Blassic is a single
self-contained binary with a minimum of dependencies), but I much
prefer something that implements the stock QBasic language like
Free Basic. A couple of the things I don't like about QBasic is it
adds a leading space to number prints and str$ conversions that
usually has to be ltrim$'d out, and binary byte reads require a
tricky subroutine (that I copy/paste from program to program), but
otherwise it's much faster to code in a language that I've used
for a long time and just intuitively know. There is a lot of
example QBasic code out there and most of it will run with
fbcscript with little or no modification.
6/27/21 - Most Linux distributions are fairly safe out-of-the-box because...
...but step outside those defaults and anything goes - any useful
operating system that runs user-installed software can also run
malware if instructed to and Linux is no different, in fact one
might have to be even more careful because unlike Windows there
are no easy-to-install "real time scan" applications that I know
of (nor would I want one due to overhead and potential system
breakage). Forget the myth that the operating system itself is
locked down and requires root permissions.. who cares, OS files
are easily replaced. It's the user files that matter and any
program or script that the user runs by default has total read and
write access to every user file. Run something bad and it's game
over. Yes perhaps Linux needs a better security model but that's
another story.
Of course the first line of defense is common sense and good
backups.. try really hard to not run sketchy stuff to begin with,
and make sure you have multiple copies of any data that matters. I
like Back In Time because by using hardlinks it can keep multiple
snapshots without too much overhead and the backup files are just
plain file copies that can be accessed and individually restored
as needed (for me, my own fumble fingers are the primary threat).
Backups of important stuff should be kept in multiple locations.
Even though personally I have never encountered Linux malware in
the wild, it does exist, it has happened and unlike fumble fingers
messing up one file, the entire user system is at risk. So
whenever I deviate from system-provided packages I take a bit of
time to check it out before running it, then after running it pay
attention to what it's doing.
For scanning downloads, I use ClamAV's clamscan along with a file
manager script and a few extra custom signatures, so before
running anything I can right-click the file or directory it's in
and run my run_clamscan script. Only takes a few seconds. ClamAV
updates itself so I don't have to worry about that and although
the majority of threats are for Windows, it also detects
Linux-specific threats. The custom signatures detect additional
suspicious combinations of script commands and although it
produces some false alarms, if something hits I want to read the
script and verify what it's doing.
The following is the script I use for scanning things with
clamscan, as written it requires clamav/clamscan, xterm for
displaying the results, and a file named "clamsigs.ldb" containing
custom signatures in the user home directory. Here's a zipped copy
of my clamsigs.ldb file.
-------------------- begin run_clamscan ------------------------------
#!/bin/bash # run clamscan with extra custom signatures/options if [ "$1" = "_doit_" ]; then # extra options here... opts="-rozid $HOME/clamsigs.ldb -d /var/lib/clamav --follow-file-symlinks=2" logfile="$HOME/clamscan_log.txt" shift if [ "$1" = "" ];then opts="$opts .";fi clamscan --version echo "Options: $opts" "$@" echo "Scanning..." echo >> "$logfile" echo "--------------------------" >> "$logfile" echo >> "$logfile" echo "clamscan $opts" "$@" >> "$logfile" echo "CWD=`pwd`" >> "$logfile" echo "running on `date`" >> "$logfile" clamscan -l "$logfile" $opts "$@" echo "------- press a key -------" read -n 1 nothing else xterm -e "$0" _doit_ "$@" fi
-------------------- end run_clamscan --------------------------------
The scan results are appended to "clamscan_log.txt" in the home
directory. The scan options are -r for recursive, -o to suppress
file OK messages, -z to print all matches (not just the first
match), -i to display only infected files, the first -d for the
custom signature file, the 2nd -d for the stock clamav signatures,
and --follow-file-symlinks=2 to always follow symlinks.
Here are a couple FreeBasic "scripts" I use for encoding and
decoding ClamAV signatures...
-------------------- begin encodeclamsigs.fbc ------------------------
#!/usr/local/bin/fbcscript 'encodeclamsigs.fbc - version 210115 'encode text-string-based clamav sigs 'assumes Target:0 signatures, edit output file if otherwise 'Input format... (same as produced by decodeclamsigs.fbc) 'Signature Name: name of signature 'Signature List: list of sigs, passed directly to field 3 'Sig 0:signature 0 'Sig n:last signature n referenced in Signature list 'Sig number is for comment only, everything after : is encoded until newline 'For each Sig each character encoded as hex pair except for... '{...} passed as-is if in proper format - {[n][-][m]} where n/m are numbers '( | and ) chars passed as-is if in proper format - (a|...) or ([xx]|...) '(L) (B) and !(...) formats supported but beware of ascii conflicts ' change extended=1 to extended=0 below to disable '[0A] - hex encodings, passed as 0a - only triggered for [xx] 'use [??] for wildcard bytes, [**] to skip any number of bytes 'empty lines and lines beginning with # are ignored, otherwise 'any deviation from the basic format is flagged as error extended=1 'support for (L) (B) and !(...) tags on error goto progerror input "Text signature file: ",textfile$ open textfile$ for input as #1 input "Output signature file: ",sigfile$ open sigfile$ for output as #2 firstline=1 while not eof(1) line input #1,inputline$ inputline$=ltrim$(inputline$) 'trailing space is significant! if inputline$="" or left$(inputline$,1)="#" then goto nextline if left$(inputline$,16)="Signature Name: " then if firstline=0 then print #2,"" else firstline=0 print #2,mid$(inputline$,17)+";Target:0;"; line input #1,inputline$ if left$(inputline$,16)<>"Signature List: " then goto progerror print #2,mid$(inputline$,17); goto nextline endif if left$(inputline$,4)<>"Sig " then goto progerror print #2,";"; p=instr(inputline$,":")+1:if p=1 then goto progerror paraflag=0:pipeflag=0 'for parsing (a|b|||[0A]|[OD]) etc while p<=len(inputline$) c$=mid$(inputline$,p,1) if extended=1 then d$=mid$(inputline$,p,2):e$=mid$(inputline$,p,3) if d$="!(" then print #2,c$;:goto keepparsing if e$="(L)" or e$="(B)" then print #2,e$;:p=p+2:goto keepparsing end if end if if c$="{" then 'this is a bit tricky.. allowed formats {n} {-n} {n-} {n-m} q=instr(p+2,inputline$,"}") if q>0 and (q-p)<10 and (q-p)>1 then 'brace pair found, do further checking.. doskip=1 r=instr(p,inputline$,"-") if r>0 and r<q then '- between braces n1$=mid$(inputline$,p+1,(r-p)-1) '1st number if any n2$=mid$(inputline$,r+1,(q-r)-1) '2nd number if any if n1$<>"" then if val(n1$)=0 and n1$<>"0" then doskip=0 '1st can be 0 if n2$<>"" then if val(n2$)=0 then doskip=0 '2nd if present must be >0 if n1$="" and n2$="" then doskip=0 'don't match {-} else 'no - between braces n1$=mid$(inputline$,p+1,(q-p)-1) if val(n1$)=0 then doskip=0 'must be a number end if if doskip=1 then print #2,mid$(inputline$,p,(q-p)+1); p=q:goto keepparsing end if end if end if if c$="[" then if mid$(inputline$,p+3,1)="]" then h$=lcase$(mid$(inputline$,p+1,2)) if h$="**" then print #2,"*"; else print #2,h$; p=p+3:goto keepparsing end if end if if c$="(" and paraflag=0 and pipeflag=0 then q=instr(p+2,inputline$,"|") if q>0 and (q-p)=2 or (q-p)=5 then q=instr(q+2,inputline$,")") if q>0 then paraflag=1:pipeflag=0 print #2,"("; goto keepparsing end if end if end if if c$="|" and paraflag=1 and pipeflag=0 then pipeflag=1 print #2,"|"; goto keepparsing end if if c$=")" and paraflag=1 and pipeflag=0 then paraflag=0 print #2,")"; goto keepparsing end if print #2,lcase$(hex$(asc(c$))); keepparsing: p=p+1:pipeflag=0 wend nextline: wend print #2,"" 'terminate last signature close print "Done." system progerror: close print "Error." system
-------------------- end encodeclamsigs.fbc --------------------------
-------------------- begin decodeclamsigs.fbc ------------------------
#!/usr/local/bin/fbcscript 'decodeclamsigs.fbc - version 210115 'decode ldb format clamav signature file to text-based format 'Output format... 'Signature File: 1st field as-is 'Signature List: 3rd field as-is 'Sig n:[decoded signature starting with 4th field as Sig 0:] '{...} strings passed as-is '* passed as [**] '?x x? and ?? pairs passed as [?x] [x?] [??] 'hex pairs converted to ascii if hex and printable 'anything else passed as-is - ! ( | ) (B) (L) etc on error goto progerror input "Signature file: ",sigfile$ open sigfile$ for input as #1 input "Output file: ",outfile$ open outfile$ for output as #2 while not eof(1) line input #1, inputline$ p=instr(inputline$,";"):if p=0 then goto ignoreline print #2,"Signature Name: ";left$(inputline$,p-1) p=instr(p+1,inputline$,";"):if p=0 then goto ignoreline q=instr(p+1,inputline$,";"):if q=0 then goto ignoreline print #2,"Signature List: ";mid$(inputline$,p+1,(q-p)-1) sn=0:p=q+1:spf=1 while p<=len(inputline$) if spf=1 then print #2,"Sig";sn;":";:spf=0 c$=ucase$(mid$(inputline$,p,1)) if c$=";" then sn=sn+1:spf=1:print #2,"":goto continueline if c$="{" then q=instr(p+1,inputline$,"}") if q=0 then goto progerror 'no closing brace print #2,mid$(inputline$,p,(q-p)+1); p=q:goto continueline end if if c$="*" then print #2,"[**]";:goto continueline 'wildcard skip h$=ucase$(mid$(inputline$,p,2)):d$=right$(h$,1):ispair=0:ishex=0 if left$(h$,1)="?" or right$(h$,1)="?" then ispair=1 if (c$>="0" and c$<="9") or (c$>="A" and c$<="F") then if (d$>="0" and d$<="9") or (d$>="A" and d$<="F") then ispair=1:ishex=1 end if end if if ispair=0 then print #2,c$;:goto continueline 'not pair, output as-is a=val("&H"+h$):p=p+1 'value, skip to next if ishex=1 and a>=32 and a<128 then print #2,chr$(a); 'ascii text else print #2,"["+h$+"]"; 'out of range and wildcards end if continueline: p=p+1 wend print #2,"" ignoreline: wend close print "Done." system progerror: close print "Error." system
-------------------- end decodeclamsigs.fbc --------------------------
Here's the decoded contents of my custom clamsigs.ldb file,
produced by decodeclamsigs.fbc...
Signature Name: Suspect Script Virus A
Signature List: 0&((1|2|3|4|5|6|7|8|9|10)|(11|12|13|14)>1,2)&(15|16|17|18|19|20|21|22|23|24|25|26|27|28|29)&30=0
Sig 0:$0
Sig 1:grep -s
Sig 2:grep {1-20}$0
Sig 3:cp {0-1}$0
Sig 4:cat {0-1}$0
Sig 5:awk {1-70}$0
Sig 6:sed {1-30}$0
Sig 7:sed {1-5}1d
Sig 8:head -{2-8}$0
Sig 9:tail -{2-8}$0
Sig 10:grep {0-10}#!/
Sig 11:head -
Sig 12:tail -
Sig 13:if {1-50} -w
Sig 14:if {1-50} -x
Sig 15:for {1-10} in *
Sig 16:for {1-10} in{0-20} ~/*
Sig 17:for {1-10} in {0-20}./*
Sig 18:for {1-10} in {1-20}grep {5-20} *
Sig 19:for {1-10} in{0-20} $HOME/*
Sig 20:for {1-10} in {1-10}find .
Sig 21:for {1-10} in {1-10}find ~
Sig 22:for {1-10} in {1-10}find $HOME
Sig 23:find (.|/){1-50}-perm
Sig 24:find (.|/){1-70}-exec
Sig 25:find (.|/){1-50}-writable
Sig 26:find (.|/){1-65}while{1-20}read
Sig 27:ls{1-10}while{1-20}read
Sig 28:ls{1-10}grep {2-10} *
Sig 29:echo{1-30}* {1-30}while{1-20}read
Sig 30:[00][00][00][00]
Signature Name: Suspect Script Virus B
Signature List: 0&(1|2|3|4)>1,2&(5|6|7|8)&9=0
Sig 0:$0
Sig 1:grep {-20}>>
Sig 2:head {-20}grep {-20}sh
Sig 3:file {-20}grep {-10}our
Sig 4:file {-20}grep {-20}sh
Sig 5:for {-10} in{-20} *
Sig 6:for {-10} in{-20}/*
Sig 7:find {-50}while
Sig 8:find {-50}-exec
Sig 9:[00][00][00][00]
Signature Name: Suspect Script Virus C
Signature List: 0&1>2&2&3&4&5=0
Sig 0:$0
Sig 1:grep {3-20}"$
Sig 2:grep {3-20}"${2-10}>>{0-3}"$
Sig 3:file {0-2}"${2-30}grep {0-10}Bour
Sig 4:for {2-10}in{0-3} $
Sig 5:[00][00][00][00]
Signature Name: Possible Script Virus (no $0)
Signature List: 0&((1|2|3|4|5|6|7|8|9|10)|(11|12|13|14)>1,2)&(15|16|17|18|19|20|21|22|23|24|25|26|27|28|29)&30=0
Sig 0:#!
Sig 1:grep -s
Sig 2:grep {1-20}$0
Sig 3:cp {0-1}$0
Sig 4:cat {0-1}$0
Sig 5:awk {1-70}$0
Sig 6:sed {1-30}$0
Sig 7:sed {1-5}1d
Sig 8:head -{2-8}$0
Sig 9:tail -{2-8}$0
Sig 10:grep {0-10}#!/
Sig 11:head -
Sig 12:tail -
Sig 13:if {1-50} -w
Sig 14:if {1-50} -x
Sig 15:for {1-10} in *
Sig 16:for {1-10} in{0-20} ~/*
Sig 17:for {1-10} in {0-20}./*
Sig 18:for {1-10} in {1-20}grep {5-20} *
Sig 19:for {1-10} in{0-20} $HOME/*
Sig 20:for {1-10} in {1-10}find .
Sig 21:for {1-10} in {1-10}find ~
Sig 22:for {1-10} in {1-10}find $HOME
Sig 23:find (.|/){1-50}-perm
Sig 24:find (.|/){1-70}-exec
Sig 25:find (.|/){1-50}-writable
Sig 26:find (.|/){1-65}while{1-20}read
Sig 27:ls{1-10}while{1-20}read
Sig 28:ls{1-10}grep {2-10} *
Sig 29:echo{1-30}* {1-30}while{1-20}read
Sig 30:[00][00][00][00]
Signature Name: Suspect Obscured Script Virus
Signature List: 0&1&2&3&4&5=0&(6|7|8|9|10|11|12|13|14|15|16|17|18|19|20|21|22|23|24|25|26|27|28|29|30|31|32|33|34|35|36|37)
Sig 0:$0
Sig 1:if
Sig 2:fi
Sig 3:then
Sig 4:done
Sig 5:[00][00][00][00]
Sig 6:f\ind
Sig 7:fi\nd
Sig 8:fin\d
Sig 9:f\i\nd
Sig 10:f\in\d
Sig 11:fi\nd
Sig 12:fi\n\d
Sig 13:f\i\n\d
Sig 14:g\rep
Sig 15:gr\ep
Sig 16:gre\p
Sig 17:g\r\ep
Sig 18:g\re\p
Sig 19:gr\ep
Sig 20:gr\e\p
Sig 21:g\r\e\p
Sig 22:h\ead
Sig 23:he\ad
Sig 24:hea\d
Sig 25:h\e\ad
Sig 26:h\ea\d
Sig 27:he\ad
Sig 28:he\a\d
Sig 29:h\e\a\d
Sig 30:t\ail
Sig 31:ta\il
Sig 32:tai\l
Sig 33:t\a\il
Sig 34:t\ai\l
Sig 35:ta\il
Sig 36:ta\i\l
Sig 37:t\a\i\l
Signature Name: Possible Script Virus
Signature List: 0&(1|2|3|4)&(5|6|7)&(8|9|10|11|((12|13)&(14|15)))>1,2&16=0
Sig 0:$0
Sig 1:for {1-20} in{0-20} *
Sig 2:for {1-20} in{0-30}/*
Sig 3:find {0-50}-wr
Sig 4:find {0-50}-ex
Sig 5:head -{1-20}$0
Sig 6:tail -{1-20}$0
Sig 7:grep -{1-20}$0
Sig 8:for
Sig 9:find
Sig 10:grep
Sig 11:cat
Sig 12:test
Sig 13:[
Sig 14: -w
Sig 15: -x
Sig 16:[00][00][00][00]
Signature Name: Possible Dangerous Delete
Signature List: 0|1|2|3
Sig 0:rm -(r|f)(r|f) (.|/|~|*)([0D]|[0A]| |;|*)
Sig 1:rm -(r|f)(r|f) $HOME([0D]|[0A]| |;)
Sig 2:rm -(r|f)(r|f) $HOME/*
Sig 3:rm -(r|f)(r|f) ~/*
Signature Name: Fork Bomb
Signature List: 0
Sig 0::(){:|:&};:
Signature Name: Might Do Raw Disk Access
Signature List: 0
Sig 0:/dev/sda
Signature Name: Might Execute Web Script
Signature List: 0
Sig 0:wget http://{4-100}sh
Signature Name: Funky Delete
Signature List: 0
Sig 0:rm -(r|f)(r|f){1-10}/*
...of course this is a very very small subset of possible bad
commands! It's merely a sampling of possible suspicious commands
chosen to minimize false alerts but match published and
theoretical examples of replicating shell code and crude trojan
attempts. See ClamAV's signatures.pdf file (there's a copy
of it here) for an explanation of the format, basically each
signature consists of a list of sub-signatures with & for and,
(.|.|.) for or, > specifying more than, >1,2 specifies more
than with at least 2 different, =0 means no match (usually to skip
binaries). Each signature uses (a|b|c) for either/or bytes, {1-50}
means skip 1 to 50 bytes, and in my text-based format, [00] [0D]
etc means byte codes and anything else is converted to hex strings
including trailing whitespace.
TaskMon
This is a script that I use to keep tabs of what processes are
running on my system... [updated 7/9/21]
--------------------- begin TaskMon ---------------------------
#!/bin/bash # TaskMon 210708 - lists new tasks # Usage... # TaskMon - List running tasks not in reference list # TaskMon saveref (or 1st run) - Create a new reference list # TaskMon addref - List running tasks and prompt to add to reference list # If not running in a terminal then launches itself in xterm # Files (created if they don't exist)... # ~/.TaskMonFiles/tasklistcurrent.txt - task list from last run # ~/.TaskMonFiles/tasklistexclude.txt - ignore list (beginning fragments) # ~/.TaskMonFiles/tasklistreference.txt - reference task list function CleanGrep { # escape [ ^ and $ to avoid grep errors (probably others!) sed "s/\[/\\\\\[/g" \ | sed "s/\^/\\\\\^/g" \ | sed "s/\\$/\\\\\\$/g" # backslashes cause error message if last char but still work # redirect grep's stderr to /dev/null to suppress error messages } if [ "$1" = "doit" ];then sens=80 # number of characters compared from task command line listdir="$HOME/.TaskMonFiles" # directory for task list files tasklistcurrent="$listdir/tasklistcurrent.txt" # currently running tasks tasklistreference="$listdir/tasklistreference.txt" # reference task list tasklistexclude="$listdir/tasklistexclude.txt" # tasks to ignore mkdir -p "$listdir" # make sure task list files directory exists # if no exclude list create a default exclude file if [ ! -f "$tasklistexclude" ];then echo "[kworker/" > "$tasklistexclude" # these change constantly fi # only show exit prompt if it launched a terminal exitprompt=1;if [ "$2" = "noprompt" ];then shift;exitprompt=0;fi # generate sorted/unique list of currently running tasks.. ps -eo args --no-headers | sort -u > "$tasklistcurrent" # if reference list doesn't exist or run with saveref copy to ref list if [[ ! -f "$tasklistreference" ]]||[[ "$2" = "saveref" ]];then echo echo "*** Creating reference list of all running processes ***" echo cp "$tasklistcurrent" "$tasklistreference" else # list new tasks newtask=n echo "Running processes that are not in reference list..." while read -r taskline;do # read lines from current task list # trim search length to reduce sensitivity, clean up grep search grepline=$(echo -n "$taskline"|head -c "$sens"|CleanGrep) # ignore tasks in the exclude list.. while read -r tl2;do # read lines from exclude list if [ "$tl2" != "" ];then # ignore empty lines gl2=$(echo -n "$tl2"|CleanGrep) # clean up search if (echo "$taskline"|grep -q "^$gl2")2>/dev/null;then grepline="";fi fi done < "$tasklistexclude" if [ "$grepline" != "" ];then # if not in ignore list (or empty) # list task if not in the reference list if ! grep -q "^$grepline" "$tasklistreference" 2>/dev/null;then echo "$taskline" newtask=y fi fi done < "$tasklistcurrent" # if run with addref then add additional tasks to ref list if [ "$2" = "addref" ];then if [ $newtask = y ];then echo echo -n "Add these tasks to the reference list? [y/any] " read -rn 1 answer ; echo if [ "$answer" = "y" ];then echo echo "*** Adding new processes to reference list ***" echo cp "$tasklistreference" "$tasklistreference.temp" cat "$tasklistreference.temp" "$tasklistcurrent" | \ sort -u > "$tasklistreference" rm "$tasklistreference.temp" fi else echo "No new tasks to add." fi fi fi if [ $exitprompt = 1 ];then echo -n "----- press a key to exit -----" read -rn 1 fi else if [ -t 0 ];then "$0" doit "noprompt" "$1" else xterm -e "$0" doit "$1" fi fi
--------------------- end TaskMon -----------------------------
The script launches itself in xterm if it detects that it is not
already running in a terminal. On the first run or if passed
"saveref" as the 1st parm (Taskmon saveref) it takes a snapshot of
all the tasks running in the system and saves it to
"tasklistreference.txt" in the home ".TaskMonFiles" directory. On
the first run it also creates a "tasklistexclude.txt" file
containing one entry - "[kworker/" - any tasks starting with an
entry in this file are not displayed to reduce clutter. I also add
/opt/microsoft/msedge-dev/ and /usr/lib/firefox/ to avoid showers
of task threads I don't care about. Once the reference is created,
running TaskMon displays any process that's not in the reference
list. If the new processes are fine then running TaskMon addref
adds the new tasks to the reference list so they won't be shown.
The idea is to filter out normal tasks so when checking out new
software I can see what it's doing. I made desktop shortcuts for
"TaskMon" "TaskMon saveref" and "TaskMon addref" along with other
task monitoring stuff - BPyTop htop etc - to keep up with what's
going on with my system.
It's not foolproof and certainly does not provide absolute
protection, but makes me feel better and certainly better than not
checking at all, especially when installing stuff that doesn't
come from official repositories. Even strictly sticking to
official repositories isn't absolute protection, repositories have
been compromised in the past (more often with extra tool
repositories not so much the distro repositories themselves) but
usually when that happens people notice bigtime, keeping up with
LWN, Hacker News, Ars Technica etc goes a long way.
YABASIC - Yet Another BASIC that can be
used for scripting
12/5/21- YABASIC is a bit different than other BASICs syntax-wise but it is functional. Unlike my other BASIC scripting solutions (blassic, fbcscript, bbcscript), yabasic is designed for scripting without hacks, is currently maintained, and is available from the stock Ubuntu 20.04 repository. The repository version (2.86.6) isn't too out of date, packages and source code for the latest version are available from the YABASIC home page. I compiled v2.90.1 from the tar.gz source with no problems, just did ./configure followed by make, already had all the dependencies (however I had no luck at all compiling the ruby/rake-based version on github). Compiling produced a single executable that can be run from anywhere, just put in any local path directory to override the repository install.
Here is my closestR program converted to yabasic...
------- begin closestR.yab --------------- #!/usr/bin/env yabasic rem a program for finding standard resistor values rem by WTN, last mod 20180117, converted to yabasic 20211205 rem no space$ function in yabasic (yab) so add a sub for it sub space$(x) :rem this is a very inefficient way to do this... local z,z$:z$="" if x>0 for z=1 to x:z$=z$+" ":next z :rem yab no then on one-line if return z$ end sub rem clear screen :rem yab clear screen instead of cls. Color is difficult. rem if clear screen is never used then ANSI can be used for color/cursor. print chr$(27),"[1;37;44m",chr$(27),"[2J",chr$(27),"[H"; :rem white on blue print "=== Resistor Value Finder ===" print "Finds the closest stock 1% and 5% resistor values." print "Entry can include K or M suffix, output is standard" print "resistor notation. Enter an empty value to exit." dim valueE96(97),valueE24(25) rem E96 values, extra decade value at the end to simplify code data 100,102,105,107,110,113,115,118,121,124,127,130,133,137 data 140,143,147,150,154,158,162,165,169,174,178,182,187,191 data 196,200,205,210,215,221,226,232,237,243,249,255,261,267 data 274,280,287,294,301,309,316,324,332,340,348,357,365,374 data 383,392,402,412,422,432,442,453,464,475,487,499,511,523 data 536,549,562,576,590,604,619,634,649,665,681,698,715,732 data 750,768,787,806,825,845,866,887,909,931,953,976,1000 for i=1 to 97:read valueE96(i):next i rem E24 values+decade data 10,11,12,13,15,16,18,20,22,24,27,30 data 33,36,39,43,47,51,56,62,68,75,82,91,100 for i=1 to 25:read valueE24(i):next i label entervalue: line input "Desired value: " desired$ :rem yab input has no comma before var desired$ = ltrim$(rtrim$(upper$(desired$))) //upper$ instead of ucase$ if desired$ = "" goto exitprogram mult = 1:num$ = desired$ if right$(desired$,1) = "K" mult = 1000:num$=left$(num$,len(num$)-1) if right$(desired$,1) = "M" mult = 1000000:num$=left$(num$,len(num$)-1) rem blassic's val() ignores trailing invalid characters so validate manually rem num$ must contain only 0-9 and no more than one decimal point E = 0:E1 = 0:PC = 0 for i = 1 to len(num$) a$=mid$(num$,i,1) if asc(a$) < asc("0") or asc(a$) > asc("9") E1 = 1 if a$ = "." E1 = 0:PC = PC + 1 if E1 = 1 E = 1 next i if E = 0 and PC < 2 goto entryok print "Don't understand that, try again" goto entervalue label entryok: rem calculate desired value from string and multiplier desiredR = val(num$) * mult if desiredR >= 0.1 and desiredR <= 100000000 goto valueok print "Value must be from 0.1 to 100M" goto entervalue label valueok: rem determine multiplier to convert stored values norm = 0.001 if desiredR >= 1 norm = 0.01 if desiredR >= 10 norm = 0.1 if desiredR >= 100 norm = 1 if desiredR >= 1000 norm = 10 if desiredR >= 10000 norm = 100 if desiredR >= 100000 norm = 1000 if desiredR >= 1000000 norm = 10000 if desiredR >= 10000000 norm = 100000 rem determine lower value match, upper match is one more rem compare to a slightly smaller value to avoid FP errors for i = 1 to 96 if desiredR > valueE96(i)*norm-0.00001 v1 = i:v2 = i+1 next i lowerE96 = valueE96(v1)*norm upperE96 = valueE96(v2)*norm rem do the same for E24 series, using norm*10 since E24 values are 2 digit for i = 1 to 24 if desiredR > valueE24(i)*norm*10-0.00001 v1 = i:v2 = i+1 next i lowerE24 = valueE24(v1)*norm*10 upperE24 = valueE24(v2)*norm*10 rem calculate error percentages for lower and upper values lowerE96error = (1-lowerE96/desiredR)*100 upperE96error = -(1-upperE96/desiredR)*100 lowerE24error = (1-lowerE24/desiredR)*100 upperE24error = -(1-upperE24/desiredR)*100 rem determine which value has less error rem in the event of a tie go with the higher value (user can pick) closestE96=lowerE96:if lowerE96error>=upperE96error closestE96=upperE96 closestE24=lowerE24:if lowerE24error>=upperE24error closestE24=upperE24 rem print the closest value and error percentages for lower/upper values print "Closest E96 value = "; rem yab multiple print items separated by , not ; R = closestE96:gosub convertE96:print R$,space$(7-len(R$)),"("; rem to detect exact matches compare to a range to avoid float errors M=0:if closestE96 > desiredR-0.0001 and closestE96 < desiredR+0.0001 M=1 if M=1 print "exact match)": goto printE24values E$=left$(str$(lowerE96error+0.0001),4) R = lowerE96:gosub convertE96:print "-",E$,"%=",R$,","; E$=left$(str$(upperE96error+0.0001),4) R = upperE96:gosub convertE96:print "+",E$,"%=",R$,")" label printE24values: print "Closest E24 value = "; R = closestE24:gosub convertE24:print R$,space$(7-len(R$)),"("; M=0:if closestE24 > desiredR-0.0001 and closestE24 < desiredR+0.0001 M=1 if M=1 print "exact match)": goto doneprintingvalues E$=left$(str$(lowerE24error+0.0001),4) R = lowerE24:gosub convertE24:print "-",E$,"%=",R$,","; E$=left$(str$(upperE24error+0.0001),4) R = upperE24:gosub convertE24:print "+",E$,"%=",R$,")" label doneprintingvalues: goto entervalue:rem loop back to enter another value label exitprogram: print chr$(27),"[0m",chr$(27),"[2J",chr$(27),"[H"; :rem yab restore normal exit :rem yab exit instead of system rem subroutines to convert R value back to standard notation rem input R containing resistor value (with possible float errors) rem output R$ containing value in standard resistor notation label convertE96: R$="error":R2$="":R1=R+0.00001:R2=R if R1 >= 1000 R2 = R1/1000:R2$ = "K" if R1 >= 1000000 R2 = R1/1000000:R2$ = "M" if R2<1 R$ = left$(str$(R2+0.00001)+"000",5) if R2>=1 and R2<100 R$ = left$(str$(R2+0.00001)+"000",4)+R2$ if R2>=100 and R2<1000 R$ = left$(str$(R2),3)+R2$ return label convertE24: R$="error":R2$="":R1=R+0.00001:R2=R if R1 >= 1000 R2 = R1/1000:R2$ = "K" if R1 >= 1000000 R2 = R1/1000000:R2$ = "M" if R2<1 R$ = left$(str$(R2+0.00001)+"00",4) if R2>=1 and R2<10 R$ = left$(str$(R2+0.00001)+"00",3)+R2$ if R2>=10 and R2<100 R$ = left$(str$(R2),2)+R2$ if R2>=100 and R2<1000 R$ = left$(str$(R2),3)+R2$ return rem end of yabasic program, tested w/ version 2.86.6 from repository ------- end closestR.yab -----------------
This was converted from the blassic version, had to add a (really
bad:) SPACE$ function, modify all single-line IF statements to
remove the THEN, change all PRINT statements to change the ";"
separator to ",", and change the (LINE) INPUT to remove the ","
between the prompt and the variable. Color in YABASIC is trickier,
instead of being "change until changed again" it has to be applied
to every PRINT. As a workaround I used ANSI color/screen codes
instead, but that only works if CLEAR SCREEN is not used, which
also disables INKEY$ and other curses-based functionality.
Nevertheless it works and at the moment is the easiest way to
script with BASIC.. sudo apt install yabasic and done.
A color version of the xtlist script
12/27/21 - I used the previous version of xtlist extensively, so fixed it up a bit. The new version uses libtree instead of lddtree to produce a colorized dependency tree for binary files, and uses rougify (from the ruby-rouge package) or GNU source-highlight to colorize source code. Also uses unbuffer (from the expect package) to trick libtree into thinking it's running interactively, otherwise it suppresses color output. Like the original, uses file to display file stats, readelf and xxd to display binary files as info and hex, and uses less to interactively page the output of all of that in an xterm window. The new version also uses "ls -la [file]" to show the file's long directory entry before the file stats, and uses "less -R --mouse -~" to preserve ANSI codes, enable mouse scroll and suppress extra ~ characters displayed after the end of the file. Enabling mouse scroll has a side effect of disabling mouse selection for copying text to the clipboard, type "--mouse" in the list window to disable mouse scrolling and re-enable copy to clipboard.
------------------ begin xtlist ---------------------------------
#!/bin/bash # # xtlist - list a text or binary file in a xterm window - 211226 # usage: xtlist "filename" # # Uses xxd for displaying binary files, minumum number of xterm columns # needed to display without wrapping is (hexbytes * 2.5) + hexbytes + 11 # As written uses rougify from the ruby-rouge package to colorize source # code, can also use source-highlight. # Change encolor=1 to encolor=0 to disable color and use plain cat. # As written uses libtree for displaying binary dependencies (link below) # and uses unbuffer from expect package to trick libtree into color output # Uses less for display, main controls are up/down arrow, page up/down, # home for beginning, end for end, q to quit (or close xterm window). # Less has a number of features, press h for help. # cols=90 # xterm columns (expands as needed for binary hex dump) rows=40 # xterm rows xtermfgcol="-fg green" # xterm forground color, "" for default xtermbgcol="-bg black" # xterm background color, "" for default xtermfont="" # extra xterm parameters #xtermfont="-fn 10x20" # xterm font, "" for default (xlsfonts for list) #xtermfont="-fn 9x15" xtermfont="-fn 7x14" hexbytes=32 # xxd hexdump bytes per line encolor=1 # 1 for colorized output, 0 to disable color textgrep=" text" # file output to determine if a text file exegrep=" ELF" # file output to determine if an ELF binary # default utilities lddutil="" # optional, utility to list ELF dependencies ptyutil="" # optional, utility to fake terminal operation viewm="cat" # required, default utility for streaming monochrome text viewc="cat" # required, default utility for streaming color text lessutil="less" # ----- edit/comment these to specify/disable utilities --------------- #lessutil="less -R" # viewer utility and options lessutil="less -R --mouse -~" # syntax-highlighting viewer for color... #viewc="rougify" # rougify from ruby-rouge viewc="rougify highlight -t igorpro" #viewc="source-highlight --failsafe -f esc -i" # GNU source-highlight # utility for listing dependencies... #lddutil="lddtree -a" # lddtree from the pax-utils package lddutil="libtree -ap" # libtree from https://github.com/haampie/libtree # command to trick libtree into thinking it's running in a terminal... ptyutil="unbuffer" # unbuffer from the expect package #ptyutil="pty" # pty from https://unix.stackexchange.com/questions/249723/ # ----- end utility edits ----------------------------- if [ "$2" = "doit" ];then export LESSSECURE=1 # disable less shell edits etc viewutil="$viewm" # adjust for color or mono operation if [ $encolor = 1 ];then viewutil="$viewc";else ptyutil="";fi file -L "$1" | if grep -Eq "$textgrep";then ( if [ $encolor = 1 ];then echo -ne "\033[1;33m";fi echo -n "ls: ";ls -la "$1" if [ $encolor = 1 ];then echo -ne "\033[36m";fi file -L "$1" | if grep ",";then # display type if not plaintext # special case for misidentified BASIC source code file -L "$1" | if grep -q " source,";then head -100 "$1" | if grep -Eqi "^rem |^print \"";then echo "(looks like BASIC)" fi fi fi echo if [ $encolor = 1 ];then echo -ne "\033[0m";fi # if using rougify... if (echo "$viewutil"|grep -q "rougify");then rtype=$(rougify guess "$1") if (echo $rtype | grep -q "plaintext"); then # if plain text viewutil="$viewm" # use monochrome streamer fi # or if rougify guess returns nothing at all... if [ "$rtype" == "" ];then viewutil="$viewm";fi if (echo "$1"|grep -iq "\.bas$");then # if .bas extension viewutil="rougify -t igorpro -l bbcbasic" fi if (head -n 1 "$1"|grep -q "^\#\!\/");then # shebang on 1st line # basic scripting languages I use.. if (head -n 1 "$1"|grep -Eq "fbc|bbc|yabasic|blassic|bacon");then viewutil="rougify -t igorpro -l realbasic" # closest w/lowercase # realbasic lexor treats text after / as comments but otherwise close fi fi fi $viewutil "$1" || # if error use monochrome streamer... (echo "Error, listing normally...";echo;$viewm "$1") ) | $lessutil else # list binary file.. display output of file command, if ELF file # also display ldd and readelf output, then list the file as a hex dump ( if [ $encolor = 1 ];then echo -ne "\033[1;32m";fi echo -n "ls: ";ls -la "$1" if [ $encolor = 1 ];then echo -ne "\033[36m";fi file -L "$1";file -L "$1" | if grep -Eq "$exegrep";then if [ "$lddutil" != "" ];then echo; if [ $encolor = 1 ];then echo -ne "\033[33m";fi echo "$lddutil output...";echo; $ptyutil $lddutil "$1" fi echo; if [ $encolor = 1 ];then echo -ne "\033[33m";fi echo "readelf -ed output...";echo; readelf -ed "$1" fi echo; if [ $encolor = 1 ];then echo -ne "\033[33m";fi echo "hex listing...";echo; xxd -c $hexbytes "$1" ) | $lessutil fi else if [ -f "$1" ]; then if ! (file -L "$1"|grep -Eq "$textgrep");then # if not a text file xddcols=$[$hexbytes/2 * 5 + $hexbytes + 11] # calc hex dump columns if [ $cols -lt $xddcols ];then cols=$xddcols;fi # expand as needed fi xterm -title "xtlist - $1" -geometry "$cols"x"$rows" \ $xtermfgcol $xtermbgcol $xtermfont -e "$0" "$1" doit & fi fi
------------------ end xtlist -----------------------------------
I use this script from the file manager's script folder (natilus
or caja), and have differently-named versions with different
options - one set to use rougify as above, another to use
source-highlight, and another with source code highlighting
disabled. Rougify has a few useful settings for BASIC (bbcbasic
realbasic and vb) and I like its bash highlighting...

Source-highlight does a good job listing HTML...
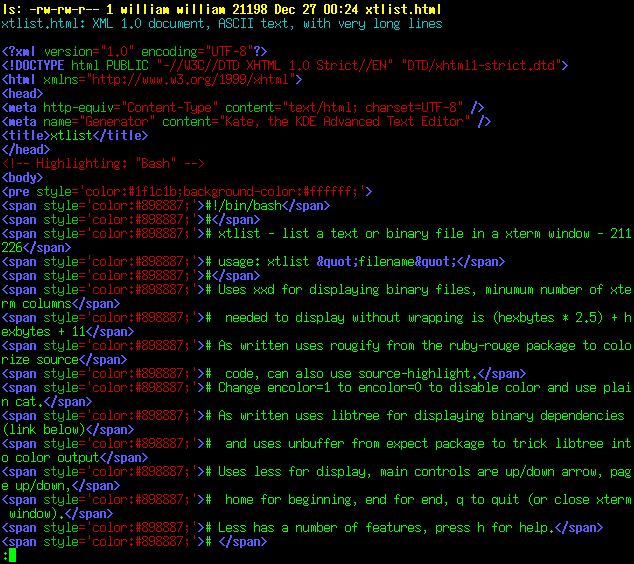
Binary files are listed in hex using xxd, elf files also include
lddtree and readelf output...
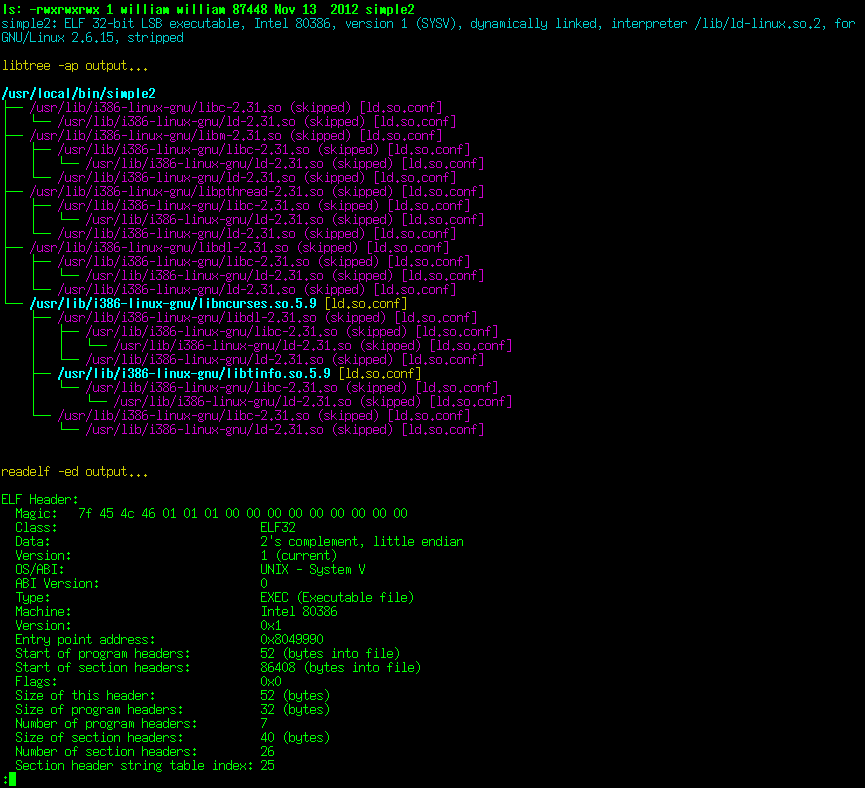
Fun stuff, and useful too. Now to find an ANSI-to-HTML
converter... ansi2html from the colorized-logs package. With this
and a syntax-highligher like rougify, scripts can be colorized for
display using a command something like...
rougify highlight -t igorpro "sourcefile" | ansi2html -w > "sourcefile.html"
Enter "rougify help style" in a terminal for a list of themes to
try after -t. For my simple web work flow I copy/paste the
resulting output from SeaMonkey Browser to SeaMonkey Composer,
works great.
. . . . . . .
2021 is almost done, 2022 here we come. New notes will be added
to the Ubunu Stuff,
Continued page.
Terry Newton (wtn90125@yahoo.com)