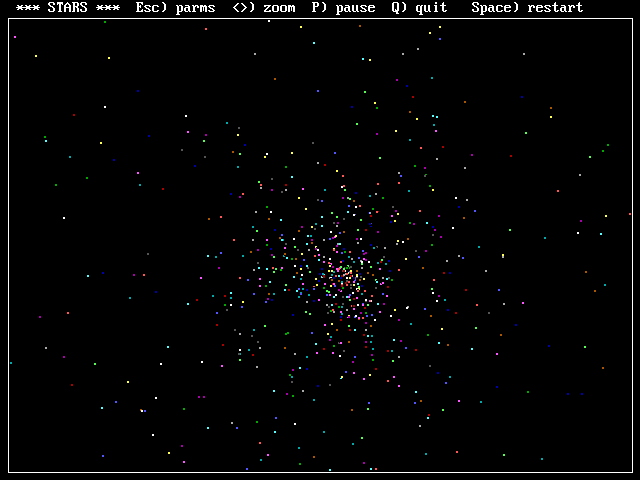
Back in the '80's I used to play around with a program called
CLUSTER, based on gravitational equations published in a Scientific
American article entitled "A Cosmic Ballet" by A.K.Dewdney and
reprinted in his 1988 book "The Armchair Universe". Back then using an
8-bit computer running at about 2mhz, I could simulate the motions of
at most a few dozen stars. Now with Ghz processors and the excellent
FreeBASIC compiler I can run simulations with hundreds or even
thousands of stars...
The stars are colored according to their masses... and
unrealistically, there is no such thing as a green star.
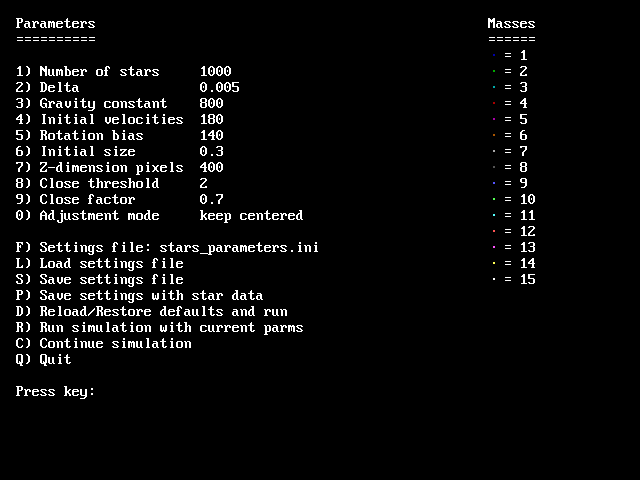
Here's the screen for adjusting the simulation parameters, which
also shows the mass color scheme...
In this program I calculate
the accellerating force felt by each star as mass of the other
star divided by distance squared, summed for every other star. In the
original article it is mentioned that
the force is the "product" of the masses divided by distance squared,
however this results in the "weight" force of an object, which is only
felt if an object is constrained from moving. The accelleration force
felt by an object in freefall does not depend on its own weight - a 2kg
object weighs twice as much as a 1kg object but only if constrained, in
a free-fall an object is weightless and falls at the same
rate regardless of its mass. So.. if computing gravitational force as
(mass_object*mass_other)/d^2, it has
to be followed by force=force/mass_object to derive the accelleration
force. Simply doing mass_other/d^2 to compute only the accelleration
force produces the same results and avoids extra steps and potential
math issues when the two masses are hugely different.
Regardless of the math specifics, computing motions this way can
never be fully accurate as it results in discrete steps - the greater
the distance a point moves between the steps, the less accurate the
simulation. This is the "N-body problem". In the program,
accellerations and motions are multiplied by the delta variable, which
determines the amount of simulated time between each step. Smaller
delta values result in a more accurate simulation but take longer to
compute, so it's a tradeoff. The discrete nature of the simulation
greatly amplifies the effects of close encounters, so to compensate
when objects are closer than the close threshold setting, the force is
reduced to soften the effect and reduce the frequency of ejections from
the cluster. Also, distance units in this program are purely arbitrary
(determined by the mass units and gravity constant), and the
speed-of-gravity (equal to the speed-of-light) is not considered. This
program is mostly just a playtoy for watching a collection of particles
crash into each other and (sometimes) settle into a dynamic structure
that resembles a star cluster. Still loads of fun (for me anyway:-) and
an opportunity to learn more about the nature of gravity.
Even in simple form, the program could use more work... for one
thing a better random start, the present version simply pushes each of
the four quadrants in different directions.. although that's kind of
cool too, it tends to create individual clusters which then merge
together. Work in progress... an easy option would be to also set each
of the four clusters spinning. A harder option would be to use ATN etc
to calculate the angle of each point then use SIN and COS to apply a
vector with a velocity based on the distance from the center.
While browsing the Astronomy
Picture
of
the Day site I found this simulation of galaxy
mergers produced by the folks from the N-Body Shop... way
cool. More videos are on their YouTube channel.
Simulations
like
these require lots of time on powerful
supercomputers... way out of reach of anything that could be made on a
home PC, but there are a few tricks that can be used to maybe beef it
up to the point of simulating more than just globular clusters on a
normal computer. One trick that can greatly speed up such simulations
is to run a full iterative n-body formulaes on only a small area
surrounding the point being computed, and average the masses of distant
points. This reduces the number of calculation sequences per time step
from n^2 to more like n^1.5.. for a field of a million points that's a
speedup of about a 1000.
A more practical way to do stuff like this would be to rig up a
compute engine... the Adapteva Parrallella
"supercomputer"
board looks very interesting... 16-64 cores delivering up to 20-70
GFLOPS
using only about 5 watts... but the FP units support only
single-precision math.
That might be good enough, with the STARS program there isn't much
difference between single and double precision as far as the gross
results, but single-precision math breaks down for tight orbits when
the delta variable is too small. Added defdbl a-z to stars.bas to use
double-precision math.. doing it this way (rather than using # after
variable names) is almost as fast with FreeBASIC as single-precision so
made that the default. But back to the compute engine.. the Parallella
board might not exactly be a real super-computer (and as of 1/8/13
isn't generally available yet), but the concept is very attractive -
unlike GPU-based products, each core is an independent processor with
both local and shared memory, the thing runs Ubuntu and is practically
an independent low-power PC, with dev tools for programming in regular
C, all for a target price of $100 for the 16-core version. It just
sounds lots cheaper and easier than GPU programming, something a hobby
hacker like me could make work without too much actual work (and
problems like this are inherently parallel, subdividing to any number
of cores is trivial). The main attraction is being able to dump
compute-intensive tasks onto it and letting them churn for however long
it takes, rather than tieing up my PC.
Last modified January 8, 2013